精读笔记
Problem Setting
这篇论文实际解决的是 VLN 中多步指令与中间视觉观察的细粒度对齐问题。真正困难点在于:现有方法一次性输入整条指令,模型必须隐式地自行切分并匹配视觉-语言语义,这在长轨迹中极易产生 grounding 歧义。任务的关键矛盾不是“看不懂指令”或“看不清环境”,而是缺乏一个显式的、逐步的中间对齐机制来桥接语言子目标与视觉观察。
Motivation
已有路线不够,是因为它们把子指令对齐当作隐式表征学习的副产品——无论是 Transformer 的交叉注意力还是 mLLM 的上下文推理,都没有显式约束“当前步骤应该对应哪一段指令”。作者的核心观察是:这种隐式对齐在长程导航中不可解释、不可控、难以 debug。关键缺口在于,需要一个即插即用的显式模块,将长程复合指令分解为阶段性子目标,并动态告诉 navigator“你现在只看这一段”。
Core Idea
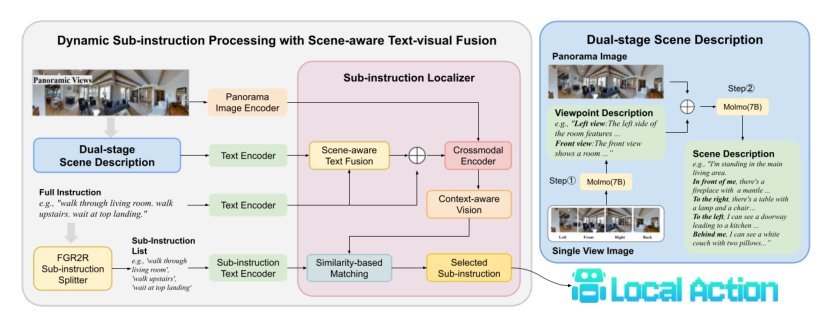
论文真正的核心思想是“显式进度追踪”:将导航指令视为可索引的子程序序列,在每一步显式预测当前应激活的子指令索引,并只将该子指令送入下游决策模块。这引入了一个强归纳偏置:导航是阶段性的,且当前视觉观察应与某个特定子指令独占对齐。配合场景描述模块把视觉信息文本化,本质上是把跨模态匹配问题从“图-文”空间转移到“文-文”空间,显著降低了匹配难度。与 prior 的本质区别在于:它不是让模型在内部隐式地“感受”进度,而是把进度外化为一个可监督、可解释的离散变量,重新组织了信息流。
Method
关键机制只有两点。第一,Sub-Instruction Localizer:通过门控融合与跨模态编码,将当前全景视觉和场景描述映射为查询向量,与子指令表征做相似度匹配,显式输出索引。它在解决的是“当前步骤该用哪段指令”的显式选择问题,核心变化是把全局指令输入替换为动态局部输入。第二,Dual-stage Scene Description:利用 VLM 先做方向视图描述再做全景融合,解决视觉-语言语义鸿沟。但它真正的必要性在于为索引预测提供与子指令同模态的文本上下文,而非单纯的视觉增强。没有场景描述,纯视觉-文本直接匹配在 R2R/R4R 的语义鸿沟下可能难以支撑准确的子指令检索。
Key Insight / Why It Works
方法真正有效的原因,最可能是显式子指令监督提供了一种强进度信号(progress monitoring),将长程决策分解为局部子任务,降低了策略学习的有效深度。这与课程学习(curriculum)和分层强化学习(options)的思想相通:显式结构比端到端隐式纠缠更容易优化。场景描述模块虽然有效,但更像 engineering / scaling——本质上是用现成 VLM 做特征增强,其增益可能来自更强的文本语义覆盖而非架构创新。核心贡献应归因于“显式中间监督”而非网络结构本身。需要警惕的是:如果剥去 FGR2R 的子指令标注,该方法是否仍能成立?文中未给出答案,因此所谓“显式对齐”的能力可能主要来自数据覆盖和标注红利。
Relation To Prior Work
与 FGR2R(Hong et al., 2020a)的关系:FGR2R 提供了子指令标注,但仅作为数据增强;Sub-Aligner 则将其升级为显式建模的即插即用模块。与 DUET:DUET 是骨干,Sub-Aligner 作为外挂模块,不改变原有全局-局部表征框架。与 MapGPT 等 mLLM 零样本方法:解决的是 mLLM 在长程轨迹中细粒度对齐漂移的问题。与早期隐式子指令学习工作(Ma et al., 2019a 等)的本质差异在于:那些方法将子指令 grounding 与导航策略联合隐式训练,而 Sub-Aligner 将其显式解耦为独立的索引预测任务,可直接干预和解释。它属于“显式结构化解耦”技术谱系,而非“更强表征”或“更大模型”路线。
Dataset / Evaluation
实验覆盖 R2R 与 R4R 的 val-unseen 和 test-unseen,包含微调(DUET)与零样本(MapGPT)两种设定。Benchmark 确实验证了“显式子指令对齐可提升性能”这一核心 claim,但未能充分验证“模块设计的优越性”——因为所有实验都依赖 FGR2R 的子指令标注作为监督,缺少“无子指令标注下的弱监督/自监督”对照。Evaluation 的明显 limitation 在于:仅离散室内环境,无连续空间、无真实世界/真机验证,且 R2R/R4R 的指令结构相对模板化,对模糊边界和重叠意图的考察不足。
Limitation
方法成立的前提是存在高质量、边界清晰的子指令标注(FGR2R),这直接限制了 scalability 和泛化性;在新领域缺乏此类标注时模块无法直接迁移。双阶段 VLM 不仅增加计算成本,还继承 VLM 的幻觉与偏见。更严重的是,增益归因不清晰:DUET 上仅 2% SR 提升,且文中未排除“子指令标注本身作为额外监督”带来的数据红利,因此所谓“显式对齐”的 reasoning 能力可能只是 retrieval + 数据覆盖的结果。此外,模型假设子指令互不重叠,无法处理真实语言中常见的回指、省略和意图交织。
Takeaway
- 1. 显式中间表示(如子指令索引)对长程具身任务具有普遍价值,可迁移到任何需要阶段分解的序列决策问题(如长程操作、多步骤对话)。
- 2. 用现成 VLM 将视觉观察“文本化”以桥接语言指令是一种实用但可替代的工程手段,未来更轻量的端到端视觉-文本对齐可能更 scalable。
- 3. 真正值得做的方向不是“如何更好地使用子指令标注”,而是“如何在无昂贵人工子指令标注的情况下,通过自监督或半监督自动发现显式阶段结构”,这将决定该思路能否走出 R2R/R4R。
一句话总结
该工作属于 VLN 中“显式结构化解耦”路线的即插即用实践,通过子指令索引预测将长程导航转化为阶段性局部对齐,核心贡献在于验证了显式中间监督对跨模态 grounding 的增益,但其实际效力强依赖于额外的子指令标注红利。