精读笔记
Problem Setting
VLA领域的真正瓶颈是动作生成范式的结构性分裂:AR继承LLM预训练推理但牺牲连续性;扩散保持连续性却将LLM降级为特征提取器。困难不在于任务定义或数据收集,而在于如何在一个共享backbone内同时承载离散next-token prediction与连续迭代去噪两种截然不同的计算动态,并避免表示层面的互扰。
Motivation
已有路线将AR与扩散视为零和选择。作者的关键观察是LLM的next-token prediction本质上就是一种逐步精化的迭代推理,与扩散去噪在计算结构上同构。因此缺口不在于“选哪个”,而在于“如何让LLM的迭代生成动力学直接驱动扩散过程,同时让AR获得连续几何先验”。此前扩散VLA(π0、CogACT)把LLM当黑盒条件编码器,是巨大浪费。
Core Idea
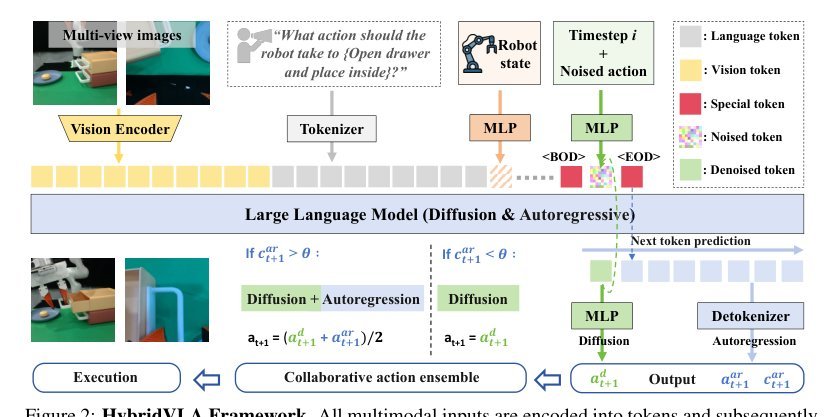
核心思想是将扩散去噪重新定义为LLM内部的reasoning iteration,而非外挂head。Noised action、timestep与条件token全部进入LLM embedding空间,每一步去噪即一次next-token prediction(预测noise residual),使扩散直接继承LLM的预训练先验。同时,AR分支通过<EOD>后的连续潜表示显式condition在扩散token上,使离散预测获得几何连续性先验。两种范式通过共享backbone和混合损失对同一条件动作分布进行双参数化近似,推理时通过置信度adaptive ensemble——本质是在test-time根据任务需求动态调度fast AR thinker与slow diffusion refiner。
Method
只保留三个关键机制:1. **Type 4 Token Sequence**:扩散token前置、AR后置,以<BOD>/<EOD>分界。这避免了AR训练时GT泄漏(扩散基于随机noise),并强制AR以连续潜空间为条件。2. **Hybrid Objectives**:同一分布的连续与离散双参数化,作为对backbone表示的互补正则化。3. **Confidence-Gated Ensemble**:以AR mean confidence为 Proxy 决定是否融合,实现两种生成动力学的test-time动态调度。
Key Insight / Why It Works
真正有效的部分可能是**通过双参数化实现的表示对齐与正则化**。扩散要求局部连续性与高维几何平滑,AR要求离散可分类性与语义可解释性,联合优化迫使隐空间同时满足两种性质,PCA证据支持这一点。但SOTA提升(17-19%)在多大程度上来自机制创新,而非训练稳定性与数据规模?消融显示无大规模预训练时性能暴跌至0.22,说明**数据覆盖是必要前提**,方法创新是增效器。另一点值得质疑:DDIM可降至4步,暗示扩散未充分利用深度迭代能力,其角色可能更接近noise-based refinement;若如此,与LLM unification的核心价值是否被高估?AR confidence阈值0.96跨不同backbone均最优,文中未给出理论解释,可能隐含着benchmark-specific的经验性。
Relation To Prior Work
与π0/CogACT/DiVLA的本质区别:prior是**feature-conditioned diffusion**(LLM→features→diffusion head),HybridVLA是**LLM-as-denoiser**(noise+timestep→LLM→denoised output)。这是从“使用LLM”到“让LLM成为扩散过程本身”的范式转换。与OpenVLA/FAST等AR VLA的区别不在于离散化技巧,而在于保留了连续动作生成的内在结构并通过连续潜空间反哺AR。技术谱系上属于unified multimodal generation在robotics的延伸,但独特贡献是将扩散迭代映射到LLM的autoregressive推理链。
Dataset / Evaluation
覆盖RLBench仿真、SimplerEnv、真实单臂/双臂任务,包括精细操作(unplug, pour)、长程任务(fold shorts)与双臂协调(lift ball)。但generalization实验的unseen objects仍是几何相似的tabletop物品,未测试跨类别泛化;real-world每任务仅100 demos,统计显著性有限。真正支持核心claim的不是sim-to-real绝对数字,而是ablation中Type 4 token sequence对比与PCA特征分析。
Limitation
方法成立依赖海量预训练(760K trajectories, 10K GPU hours)与大容量backbone,小规模场景下互扰可能占主导。推理速度瓶颈未解决:完整ensemble仍需AR生成,退化为纯扩散则丧失与prior的本质差异。AR confidence门控缺乏理论保证,在AR过度自信时可能引入错误。扩散去噪仅需4步,提示**迭代精化深度有限**,unification的边际收益可能被放大。此外,长程任务中的error accumulation与双臂协调中的state invalidation问题(一臂动作改变物体状态导致另一臂预测失效)未被根本解决。
Takeaway
- 1. **LLM-as-denoiser的insight可迁移**:将迭代优化过程(不限于扩散)嵌入LLM next-token prediction框架,适用于任何需要迭代精化的embodied任务。
- 关键不是扩散本身,而是把LLM推理链重新解释为优化迭代。
- 2. **Dual-parameterization regularization**:用离散+连续双解码器约束同一分布,是改善机器人策略表示质量的有效手段,比auxiliary learning更强因为共享同一output space。
- 3. **Confidence-guided mixture of policies**:在test-time根据模型自信度动态混合fast/slow策略,值得在更广泛embodied AI中探索。
一句话总结
HybridVLA将扩散去噪重新定义为LLM内部的迭代推理过程,通过统一token序列与双参数化混合训练使离散自回归与连续扩散在单一backbone中相互正则化,本质上是用LLM的预训练推理动力学驱动动作生成,而非仅提取其视觉语义特征。