精读笔记
Problem Setting
现有世界模型要么预测像素/通用embedding,要么假设潜在结构已知。真正困难的是:在无显式监督、多任务连续到来的条件下,如何自动学习一个既包含控制所需全部信息(sufficient)、又不携带任何冗余(minimal)的潜在表示。关键矛盾在于充分性与最小性的张力:预测像素能保证充分但绝不最小;人工设计状态因子最小但无法扩展。更棘手的是,任务相关因子往往与大量感知混淆变量共存,被动观测无法区分相关性与因果性。
Motivation
已有MBRL路线(Dreamer、TD-MPC、Efficient-Zero)把表示学习交给端到端重建或自预测目标,结果是潜在向量纠缠了光照、纹理、背景等与控制无关的感知细节。Foundation model路线(DINO、V-JEPA等)提供强先验,但embedding空间仍是通用的,未针对特定任务决策边界做筛选。作者核心观察是:人类从不基于像素级预测做规划,而是基于紧凑的、任务相关的物理/因果变量。关键缺口不是更好的预测,而是更好的筛选——一种能自动识别并只保留影响转移和奖励的父节点的机制。
Core Idea
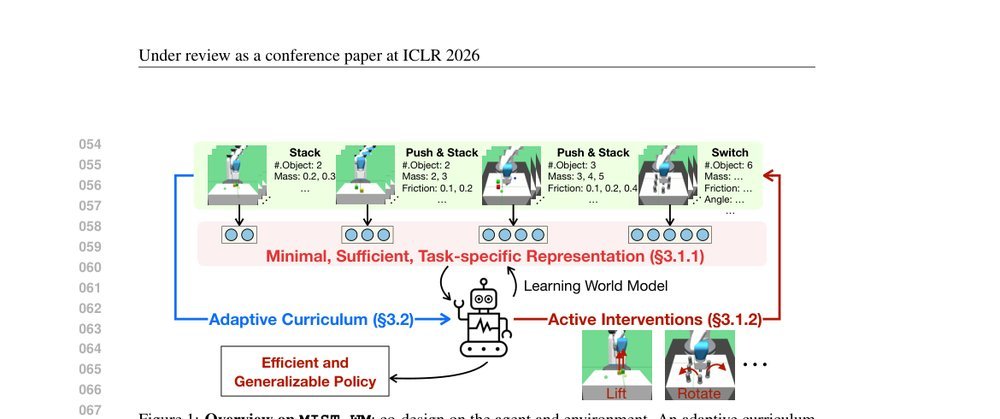
论文的核心是把世界模型从密集预测机器重新定义为稀疏因果识别器。它引入了一个可扩展的因子化动态贝叶斯网络(DBN)作为生成模型,将潜在状态显式分解为因子,并通过任务特定的稀疏掩码只保留与当前任务转移和奖励相关的父变量。这与prior的本质区别在于:不是学一个所有任务共享的flat latent vector,而是学一个结构化的、可扩展的因子库,每个任务按需激活子集。主动干预被用来替代被动观测:agent调用自监督技能库对系统执行do-calculus式的干预,通过最大化信息增益来揭示哪些潜在因子真正响应动作变化,从而在无标签情况下完成结构发现。自适应课程则确保环境以正确的顺序暴露这些因果机制,防止在结构未明时遭遇过难组合。理论上,这种设计把表示学习的归纳偏置从平滑和局部性转向了稀疏因果结构和组合性。
Method
关键机制有三: 1. 显式因子化与MIST掩码:在世界模型变分目标之外,引入结构学习恢复DBN的父节点关系,并用连续掩码mi对潜在维度做任务特定稀疏选择。这解决了表示应该包含什么的本体论问题,把无结构向量压缩变成了可解释的结构化投影。 2. 主动干预作为结构发现:面对新任务时,agent不立即学策略,而是利用预训练技能库(DIAYN/METRA)执行最大化信息增益的探索。这不是普通的最大熵探索,而是有针对性的结构探针——通过观察系统对干预的响应来识别任务相关潜变量。这解决了无监督条件下因子识别的可识别性问题。 3. 课程-模型联合调度:环境侧采用UED启发式调度器,基于模型集成不一致性(ensemble disagreement)动态选择任务参数和顺序,并与世界模型更新和策略学习耦合。这解决了何时学习何种结构的时序问题,避免在agent尚未具备必要先验时引入干扰因子。
Key Insight / Why It Works
方法有效的根本原因是把表示学习目标从预测准确切换为结构识别正确。在MIST框架下,只要DBN结构恢复正确,即使观测重建不完美,策略也能基于最小充分统计量做出最优决策;反之,重建完美的像素预测模型可能因包含冗余信息而策略脆弱。主动干预的核心价值在于打破观测数据的混杂(confounding),让agent区分与奖励相关和被动作因果影响的变量,这在被动学习中是不可识别的。课程学习的作用可能被低估——它实际上通过控制环境复杂度,将指数级增长的组合结构发现问题分解为可管理的序列。但需警惕:所谓泛化可能很大程度上得益于显式因子化和组合掩码带来的inductive bias,而非真正的因果推理;此外,DIAYN/METRA技能库的覆盖范围是隐性天花板,若技能无法触及某些环境机制,信息增益最大化将流于形式。
Relation To Prior Work
与Dreamer/TD-MPC等主流MBRL的本质差异是结构显式化:后者学的是black-box latent dynamics,MIST-WM学的是factorized graph with task-specific masking,把哪些变量驱动哪些预测从隐式网络权重中解放出来。与foundation model + RL的方法是上下游关系:MIST-WM可接在通用embedding之后做二次筛选,核心增量在于引入了任务特定的稀疏结构,而非替代感知编码。与因果表示学习(如CausalWorld)相比,MIST-WM把干预从环境给定属性转化为了agent自主行为,并与课程学习形成闭环。与UED(Dennis et al.)相比,课程不仅调度策略训练,还直接调度世界模型内部结构的发现过程。整体看,这篇论文的真正位置是因果发现、课程学习与组合表示三条线的交汇点,单点创新有限,但协同设计(co-design)是实质性推进。
Dataset / Evaluation
实验覆盖DMControl(3个locomotion)、Meta-World(8个操作)、Franka-Kitchen(5个子任务)、Robosuite(2个任务),均为标准仿真benchmark,无真实世界或真机实验。评估维度包括样本效率、跨技能泛化、物体-技能组合和未见任务。问题在于:这些benchmark中的泛化多通过物体数量、物理参数插值或已知技能重组实现,与开放域泛化差距较大;Franka-Kitchen的长程组合任务虽然被用来验证表示复用,但未明确展示MIST状态是否在长时序中保持最小性(是否存在漂移或冗余累积)。此外,实验维度仍然偏小(潜在状态维度增量有限),未能验证方法在真正高维视觉和高组合复杂度下的scalability。
Limitation
仿真到现实的鸿沟:全部在MuJoCo仿真中,主动干预在真实机器人上的安全性、执行成本和物理可行性未讨论。对技能库的隐性依赖:主动干预的有效性严重依赖预训练技能库是否覆盖足够的干预类型,这实质上是把结构发现的问题部分转移给了通用技能学习,而后者在复杂场景中同样困难。结构学习的可扩展性:DBN结构学习随潜在因子数增加复杂度急剧上升,文中未展示大规模组合(如>20个因子)的情况,可扩展性上限不清。增益归因不清晰:实验未彻底解耦课程学习和主动干预各自对最终性能的独立贡献,部分性能提升可能仅仅来自更聪明的探索(数据覆盖)或更长的训练调度,而非真正的结构发现。最小性的理想化假设:MIST状态的可识别性建立在环境可被良好因子化且干预充分的前提下,在高度非线性纠缠或部分可观测的真实视觉环境中,这一假设可能失效。
Takeaway
1. Foundation model之后需要结构化稀疏化:在foundation model提供密集embedding后,RL需要的是类似MIST的机制来做任务特定的因果筛选,这是一个值得迁移的insight。 2. 干预作为结构发现工具:主动干预不应只被视为探索,而应被视为无监督结构学习的必要组件,这对任何需要从观测中恢复隐因子的agent都有启发。 3. co-design是未来方向:agent表示与环境课程的联合优化比各自独立优化更有前景,但当前实现仍较heuristic,未来需要更形式化的共同优化目标,例如将课程调度、结构发现与策略优化纳入统一的层次化贝叶斯推断框架。
一句话总结
这篇论文属于结构化世界模型的技术演化支脉,其核心贡献在于将主动干预、因子化DBN与自适应课程三者耦合,把世界模型学习从密集预测推向任务特定的稀疏因果识别,但在大规模开放域中的可扩展性仍受限于结构推断的复杂度和预训练技能库的质量。