精读笔记
Problem Setting
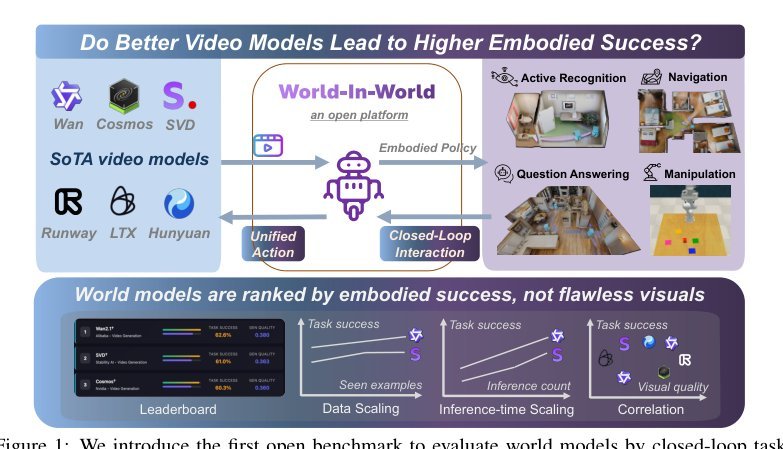
当前世界模型(WM)的评估体系存在根本性错位:社区用开环视觉指标(VBench aesthetic/quality、WorldModelBench plausibility)衡量生成质量,但embodied AI真正关心的是WM能否在agent-environment闭环中提升决策与任务成功率。真正困难点在于,异构WM(text-to-video、trajectory-conditioned、action-conditioned等)原生控制接口差异极大,缺乏统一协议导致无法横向比较;更关键的矛盾是,预训练视频生成器在互联网视频上学到的是外观分布,而非动作-观测因果对齐,因此视觉逼真度与embodied utility之间不存在单调关系。
Motivation
已有benchmark(VBench、WorldScore、WorldModelBench)全部停留在开环评估,测的是‘生成了什么’而非‘帮助agent做成了什么’;task-specific world model(如PathDreamer、SE3DS)又只在单一领域自评,无法回答通用视频生成器是否具备跨任务embodied潜力。作者意识到,视频生成技术的爆发(扩散模型、自回归模型)已经让视觉质量逼近饱和,但社区对‘这些模型作为WM究竟值多少’一无所知。关键缺口是一个能够将任意WM接入agent闭环、以任务成功为硬指标的统一评估平台。
Core Idea
核心思想是将WM从‘被动内容生成器’重构为‘主动决策基础设施’。作者提出World-In-World,通过一个与模型无关的闭环接口,把异构WM嵌入agent的感知-规划-控制循环。具体而言,统一动作API将agent的原生动作意图翻译成WM能理解的各种控制模态(文本/相机轨迹/低级动作),使不同架构的WM能在同一embodied protocol下公平竞争;在线规划策略则采用‘提案-模拟-修正’循环,让WM在每一步决策中为候选动作序列生成反事实rollout,再由revision policy评分选优。这改变了WM的评估范式:不再问‘生成视频有多真’,而是问‘agent因为有了WM预测,任务成功率提升了多少’。其本质差异在于,prior work把WM当作输出媒介来打磨,本文把它当作闭环决策系统的内部模拟器来验证。
Method
方法层面只保留三个关键机制:(1) 统一闭环在线规划。形式化为策略引导的束搜索:proposal policy采样M条候选动作序列,WM分别rollout预测未来观测,revision policy基于预测结果评分并选择最优决策。该框架比经典MPC更灵活,因为最终决策可以是高层语义答案(如A-EQA中的回答)与低层动作的联合输出,不限于纯动作序列优化。(2) 统一动作API。这是跨模型比较的工程前提,也是本文能够同时评测text-conditioned(Hunyuan、Wan)、trajectory-conditioned(NWM)、action-conditioned(SVD†)等异构WM的关键。它将agent动作映射为WM所需的控制输入,本质上建立了一套embodied control的通用语言。(3) 轻量后训练。用目标域(Habitat-Sim/RLBench)的40K级动作-观测数据对预训练视频生成器做单epoch微调,将互联网视频模型的动作空间与下游任务对齐。该设计让研究可以分离‘预训练视觉质量’与‘下游动作可控性’各自对闭环成功的贡献。
Key Insight / Why It Works
方法之所以能提升任务成功率,根本在于将WM的评估/使用方式从‘像素保真’切换为‘决策有用性’。闭环规划并不要求WM生成完美逼真的未来,而只要求它在候选动作之间保持正确的相对排序(ranking)——即让agent能区分哪些动作更可能导向成功。这正是为什么即使视觉质量一般的模型,只要动作可控性高,就能在闭环中表现优异。
三个核心发现中:‘可控性>视觉质量’是最本质的洞察:预训练视频生成器学会了出色的外观先验,但缺乏动作-观测的因果对齐;embodied tasks需要的是细粒度控制忠实度,而非电影级画质。‘后训练数据扩展优于升级预训练模型’暗示:embodied utility主要来自表示空间与动作条件的对齐,而非模型容量或预训练数据的盲目扩大,这为领域提供了务实的资源分配策略。‘推理时计算扩展有效’本质上是test-time compute via rollouts:更多候选序列的模拟带来更鲁棒的期望奖励估计,符合model-based planning的基本逻辑,但本文首次在现代大规模视频WM上量化了这一规律。
哪些是工程/scaling?统一API主要是接口桥接;在线规划框架是标准MPC的实例化;后训练是常规的domain adaptation。本文的真正学术价值在于系统性地量化了‘开环-闭环鸿沟’,并建立了一个新的评估基准。
Relation To Prior Work
与VP2(Tian et al., 2023)最接近,但VP2只涉及早期视频预测架构和简单控制任务,无法覆盖现代扩散/自回归视频生成器。与WorldScore(Duan et al., 2025)的区别在于,后者仍是开环评估(图像+相机轨迹→视频),缺乏agent与环境的交互闭环。与PathDreamer、SE3DS、NWM等task-specific WM的区别在于,本文将专用模型与通用视频生成器放在同一闭环protocol下比较,证明了通用视频模型经轻量后训练即可在embodied决策中匹敌甚至超越专用模型,模糊了‘task-specific world model’与‘generic video generator’的界限。
技术谱系上,本文属于‘world model as decision-making infrastructure’与‘embodied AI evaluation’的交叉。真正新增的信息是:通用视频生成器的embodied潜力被严重低估,而瓶颈不在生成质量,而在控制接口的对齐;同时,闭环评估范式本身比任何单一模型改进都更能推动领域进步。
Dataset / Evaluation
覆盖四个互补任务:主动识别(AR)、图像目标导航(ImageNav)、主动式具身问答(A-EQA)和机器人操作(Manipulation),跨越Habitat-Sim和CoppeliaSim/RLBench。这在仿真层面提供了一定的任务多样性(感知、导航、语言推理、操作),但全部局限于仿真环境,无真实机器人或真实世界部署验证。
Benchmark有力支撑了核心claim:Figure 2和Table 1清晰显示VBench视觉高分模型(如Runway Gen4、Wan2.2 A14B)与闭环任务成功率无显著正相关,部分post-trained小模型(如SVD†)在导航任务上反超。然而,评估仍有明显局限:操作任务仅4个RLBench任务,且horizon短;长程规划测试不足(最长L=14);场景全为静态室内,缺乏动态物体和复杂物理交互。此外,revision policy在不同任务中差异较大(VLM scorer vs. LPIPS),这使得跨任务的‘WM本身能力’比较带有一定的策略耦合性,文中未完全解耦。
Limitation
方法成立依赖强前提:预训练模型必须具备可微调的基础视觉先验,否则后训练无法挽救。跨域实验(HSSD→HM3D/MP3D)显示性能显著低于域内后训练,表明模型学到的更多是场景布局统计和外观关联,而非可迁移的物理规律或通用空间推理,所谓泛化可能主要是benchmark overlap。
物理建模天花板明显:操作任务中接触力、摩擦、关节物体状态变化几乎无法被视觉WM捕捉(Table 3增益微弱),当前视觉WM在接触密集型任务上的闭环价值非常有限,本质上仍停留在‘视图变化预测器’层面。长程状态累积机制缺失:论文承认WM缺乏长期时空历史积累,panorama输入的增益不一致说明全局上下文未被有效利用,agent仍依赖短horizon贪婪规划。
计算开销与真实部署鸿沟巨大:每个决策步需多次WM rollout(最多11次/步),且每次rollout本身是多步视频生成,这种成本在真实机器人部署中几乎不可承受,当前框架更像是离线评估工具而非在线控制方案。增益归因模糊:Table 5显示简单LPIPS scorer在ImageNav上优于VLM scorer,暗示有时‘看rollout’本身比‘rollout质量’更重要,WM的闭环增益部分可能来自revision policy对rollout的二次推理,而非WM预测本身的因果忠实性。
Takeaway
- 1. 评估范式必须转向闭环:本文最重要的遗产是确立‘任务成功率而非视觉质量’作为WM的首要评估指标。
- 未来任何WM论文都应报告闭环embodied performance,否则难以声称对决策有用。
- 2. 轻量后训练是关键杠杆:对于已有强预训练视频模型,投入资源进行动作空间对齐(post-training)的回报远高于盲目扩大预训练规模。
- 这一洞察可直接迁移到自动驾驶、机器人操作等领域,降低entry barrier。
一句话总结
World-In-World通过建立首个跨任务闭环评估框架,系统性地证明了通用视频生成器经轻量动作对齐后可在具身决策中替代专门世界模型,其核心推动在于将世界模型的评估标准从视觉逼真度转向闭环任务成功率,并揭示了可控性与推理时计算相比模型规模对embodied utility更具决定性。