精读笔记
Problem Setting
现有VLA面临一个根本矛盾:操作数据集分布窄、语义贫乏,直接微调VLM会灾难性遗忘其开放域推理能力;而简单地将VL与操作数据共训练又无法有效激活VLM的推理来指导底层闭环控制。真正困难点在于,如何在同一个模型中让'高层语义推理'与'低层精确控制'共存且互不腐蚀,使机器人能遵循开放式自然语言指令(如'把酸一点的水果放到不那么酸的那个旁边')完成zero-shot操作。
Motivation
作者核心观察是:当前两条主流路线各有致命缺陷。统一自回归共训练(RT-2/Magma)把操作和VL数据混在一起训,但未解决任务干扰,导致VLM的推理能力在操作任务中'沉睡';嵌入CoT的操作数据方法(ECoT)虽然尝试引入推理,但依赖action-pretrained架构和固定推理格式,既限制表达自由度,又无法避免VL能力遗忘。关键缺口在于:VLA需要一种机制,让VLM像'指挥官'一样持续运行,而不是被操作数据'重写'。
Core Idea
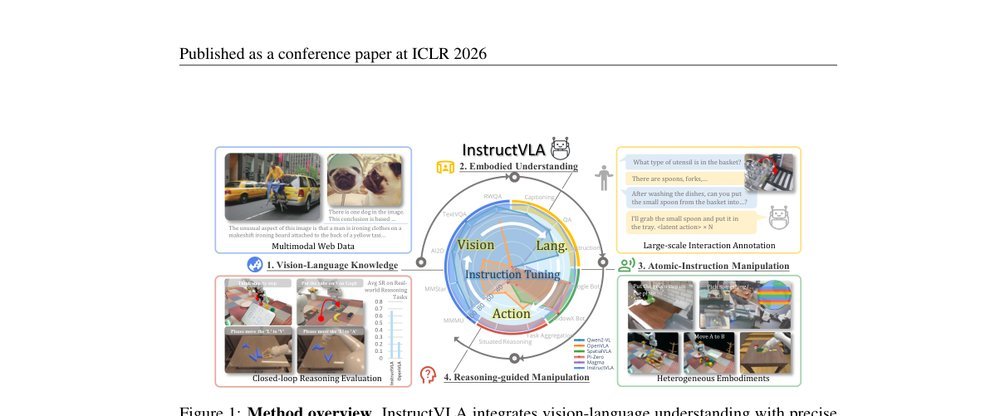
论文的核心思想是将VLA从'视觉-语言到动作的端到端映射'重新定义为'指令跟随框架下的多模态推理与动作生成交替问题'。关键洞察是:动作生成应该和语言回复一样,成为VLM输出token的一种模态,但需要通过潜在动作(latent action)和MoE路由,实现高层推理流与低层控制流的显式解耦与按需融合。
具体来说,作者引入可学习的latent action作为VLM与动作专家之间的'意图接口':VLM只负责输出抽象的动作意图(通过latent action token表达),而具体的连续动作解码交给独立的flow matching action expert。这创造了一个信息瓶颈,防止操作数据的底层细节梯度反向传播并污染VLM的语义空间。同时,MoE adaptation让模型根据当前上下文动态决定激活'推理专家'还是'动作专家',使得推理与执行可以在同一个自回归框架内交替进行,却不共享参数子空间。与prior的本质区别在于:不是试图让VLM直接'学会动作',而是让VLM'学会指挥一个动作专家',并通过两阶段训练确保VLM的预训练知识不被覆盖。
Method
关键机制有三:(1) Latent Action Queries。在VLM的输出层引入N个可学习query,从VLM hidden states中提取latent action representation。它解决的是'VLM如何在不输出底层动作的情况下表达操作意图'的问题。核心变化是:建立了一个与语言token同构但语义抽象的中间层,使VLM的输出空间得以扩展而不被破坏。(2) MoE Adaptation。在LLM backbone中并行配置language LoRA与action LoRA,通过scalar head预测gating weight。它解决的是'推理与执行的任务干扰'问题。核心变化是:不再用同一组参数处理多模态推理和动作生成,而是让输入上下文自适应地路由到不同子空间,实现参数级别的隔离。(3) 两阶段训练与Flow Matching Action Expert。Stage 1仅训练action expert与latent action嵌入(650M参数),在操作数据上建立VLM到动作的'方言'接口;Stage 2冻结action expert,仅训练MoE模块(220M参数),在VLA-IT和多模态数据上学习如何用自然语言推理驱动该接口。独立的action expert采用flow matching解码连续动作。核心变化是:通过参数冻结与课程式对齐,将'学习新动作'与'保持旧知识'解耦。
Key Insight / Why It Works
方法真正有效的原因不是某个单一模块的先进性,而是'解耦+重组'带来的系统级收益。
首先,latent action不是简单的动作tokenization(如FAST),而是一个人为构造的信息瓶颈。它迫使VLM停留在'意图级别'的抽象表征,而非直接回归底层动作细节,这是保留VLM开放域能力的关键。其次,MoE本质上是一种任务特定的子空间学习:操作数据的梯度主要流向action expert,语言/推理数据的梯度流向language expert,这比全量微调(OpenVLA)或简单共训练(Magma)更有效地保留了原始语义空间。第三,两阶段训练相当于先建立'动作方言'(Stage 1),再学习'调用协议'(Stage 2),这种curriculum避免了同时学习新表示和新推理目标的不稳定性。
但需要做技术判断的是:SimplerEnv-Instruct上96%的提升,可能部分来自VLA-IT数据集对benchmark指令分布的高覆盖(数据驱动),而非纯粹的推理transfer。真实世界math/OCR任务的收益,本质上是VLM预训练能力(OCR、算术)通过latent action接口被'释放',而非在具身域中习得了新推理能力。因此,核心贡献更像是'有效隔离并释放预训练能力',而非'创造了新的具身推理能力'。MoE和latent action的作用,本质上是更好的工程手段来实现这种隔离。
Relation To Prior Work
与RT-2/OpenVLA/SpatialVLA等'Action-only VLA'相比,prior将VLM视为更好的视觉编码器和初始化权重,微调后VL能力丧失;InstructVLA将VLM视为持续运行的推理核心,通过参数隔离避免遗忘。
与Magma/RT-2(共训练)相比,Magma缺乏有效的任务隔离机制,推理与动作在同一个latent空间中竞争;InstructVLA通过MoE和latent action显式分离两个子空间,并通过门控动态组合。
与ECoT/Emma-X相比,这些工作将CoT硬编码进操作数据,推理格式固定且局限于操作域;InstructVLA保留了VLM的自由形式推理能力,并通过VLA-IT数据将开放域QA/captioning与操作关联,实现了真正的多模态推理-操作统一。
与π0/GR00T等flow-based方法相比,这些工作用flow matching做动作生成但完全放弃自回归文本推理;InstructVLA将flow matching限制在action expert内,同时保留VLM的自回归文本生成,属于'hybrid'架构。
技术谱系上,这篇工作属于'Adapter-based VLA with structured reasoning decoupling',受LLM PEFT和MoE启发,首次系统性地将其用于解决VLA中的灾难性遗忘与推理-控制耦合问题。
Dataset / Evaluation
数据层面,650K VLA-IT样本基于Bridge/Fractal等数据集,通过GPT-4o进行指令重写、上下文创建和场景QA标注。其价值在于将窄分布的操作数据扩展为支持开放指令跟随的多样化语料。但局限明显:仍局限于桌面基本操作(pick/place/open/close),未覆盖灵巧操作或长程任务。
评估层面,提出的SimplerEnv-Instruct(80任务,分Task Aggregation和Situated Reasoning)是首个专门诊断VLA指令跟随与常识推理的benchmark,设计合理。但1.1K trials规模偏小,且任务以短程为主,难以区分'真正的推理泛化'与'训练数据中的指令模式记忆'。真实世界实验(WidowX zero-shot和Franka few-shot)验证了闭环可行性,但设置相对简单。
核心疑虑在于:benchmark的提升幅度是否真正证明了推理对操作的增益,还是主要证明了'不遗忘VLM能力'本身的价值?文中缺乏反事实实验(如用同样数据但破坏VL能力后的对比)来量化推理的边际贡献。
Limitation
方法成立强依赖于latent action作为有效的信息瓶颈,但其可解释性与最优维度选择文中未深入分析。虽然保留了VL能力,但Table 1显示Generalist在部分纯VL benchmark上仍略低于基线Eagle2,说明完全无遗忘难以实现。
更具根本性的局限是:所谓'推理增强操作'的增益,可能主要是'预训练VL能力的保持与释放',而非在具身域中涌现出新的推理形式。在math/OCR等任务上,模型只是做了一个'会看图的计算器',并没有展示出物理层面的推理。
另外,MoE的必要性可能被夸大:如果操作数据量达到π0.5级别(10K+小时),全量微调配合更大模型是否仍需要MoE隔离?文中未在同等数据规模下验证MoE的相对优势,因此其在scaling law中的位置不明。
SimplerEnv-Instruct的评估以单步/短程指令为主,涉及真正长程规划(多步子任务分解并执行)的验证不足。offline benchmark与真实部署之间仍有鸿沟,特别是缺乏对失败案例中推理-执行不一致性的深入分析。
Takeaway
- 最值得记住的几点: 1. 对VLA领域而言,'保护VLM开放域推理能力'比'直接优化操作准确率'更具长期价值,而保护的关键在于'参数隔离与接口解耦',而非'数据混合与全量微调'。
- 这提示未来VLA应更多借鉴LLM的PEFT/Adapter路线。
- 2. Latent action作为'跨模态意图接口'是可迁移的范式:在任何需要高层语义模型指导低层控制/生成的场景(如具身导航、多模态生成)中,类似的瓶颈设计都能防止高层模型被低层数据污染。
- 3. VLA-IT的数据工程范式(通过LLM丰富指令多样性、场景QA、上下文创建)证明了:即使在有限的操作数据集上,也可以通过数据重标注构造出支持开放指令跟随的训练信号。
一句话总结
InstructVLA通过latent action接口与MoE适配将VLM的推理流与动作生成分离,以'保活而非重塑'的思路在小型VLA中实现了开放域推理与闭环操作的共存,但其核心收益本质上来自对预训练VL能力的有效隔离与释放,而非在具身域中培养出新的推理能力。