精读笔记
Problem Setting
VLN的核心瓶颈已从'如何编码语言-视觉对齐'转向'如何在感知不可靠时做出安全决策'。现有agent在视觉证据不足(如多扇相似的门)、空间线索歧义(如遮挡导致的 traversability 不确定)时频繁失败,根源在于它们将感知输出视为确定性输入,训练目标强制agent在任何confidence水平下都输出action。真正需要解决的是:将感知层面的结构性不确定显式注入决策空间,而非仅在下游用attention隐式加权。
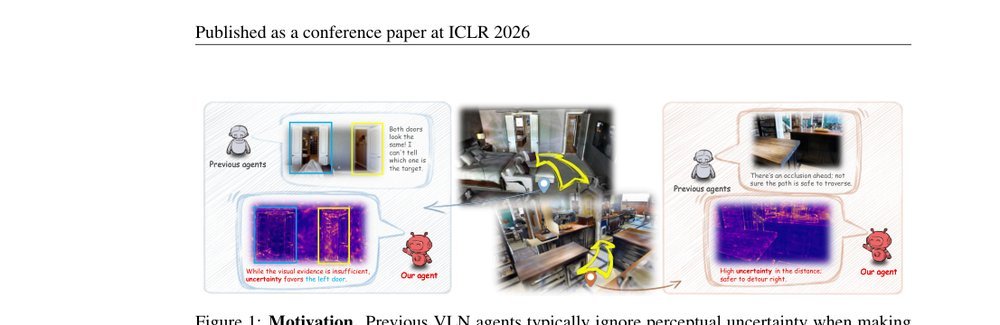
Motivation
地图化VLN方法(voxel、grid、3DGS)追求更精确的场景重建,但决策时仍采用'所见即所得'的确定性逻辑。作者的关键观察是:在导航中,'知道哪里不确定'和'知道场景结构'同等重要。遮挡、重复纹理、视觉相似物体带来的不是需要被平滑掉的噪声,而是关于行动可行性和grounding可靠性的信号。已有工作缺乏一种与显式3D表示同构的不确定性量化机制——uncertainty要么被完全忽略,要么仅在动作分布层面隐式表达(如VLN-Copilot),无法与空间结构绑定。缺口在于:需要把不确定性当作场景表示的内在维度,而非决策后处理。
Core Idea
论文的核心不是'把3DGS用到VLN'(这已被3DGS-VLN探索),而是将3D Gaussian的显式参数结构重新定义为不确定性估计的物理锚点。每个Gaussian primitive不仅是几何/语义的载体,更是一个'可扰动的假设':通过对其position、scale、semantic attributes引入变分扰动,将后验分布的离散度转化为空间化的几何/语义不确定性;同时利用Fisher Information将渲染敏感度转化为外观不确定性。这些不确定性不独立存在于决策层,而是直接attach到场景原语上,形成3D Value Map——一个同时编码'世界是什么'和'我们有多确定'的联合场。这改变了传统pipeline的信息流:从observation → deterministic feature → action,转变为observation → explicit probabilistic field → structured value map → action。其inductive bias在于:3D Gaussian的参数可解释性使得uncertainty与物理空间天然耦合,agent可以在具体空间位置上进行可靠性的显式推理。
Method
关键机制可拆解为三点。第一,Semantic Gaussian Map作为可微基座:通过RGB-D初始化并用可微渲染优化,赋予每个primitive语义属性(SAM2+CLIP),提供精细的几何-语义联合表示。这比voxel/grid更紧凑,且每个primitive的参数可独立扰动。第二,同构的三种不确定性估计:几何和语义不确定性通过变分推断实现——对position/scale和semantic attributes学习变分后验,以方差度量可靠性;外观不确定性则用Fisher Information近似Hessian,避免二阶导数计算,同时度量渲染对局部扰动的敏感度。这里的关键是uncertainty估计与表示共享同一套参数空间,无需额外latent encoder。第三,3D Value Map的决策融合:将uncertainty作为Gaussian表示的附加维度,通过projector嵌入后与指令交互。uncertainty不再是一个标量confidence,而是空间化的field,直接作为affordance(如避开高uncertainty区域)和constraint(如不信任高语义歧义的landmark)参与action prediction。
Key Insight / Why It Works
方法真正有效的根源在于'结构化的感知置信度'。传统VLN的attention机制隐式学习'看哪里',但attention weights缺乏物理对应性;本文的uncertainty与每个Gaussian的position/scale/semantics显式绑定,使agent获得了'在空间中的具体位置知道是否可靠'的能力。Ablation中最有信息量的发现是:在简单场景中压制uncertainty几乎不影响成功率,但在复杂场景(遮挡、重复结构)中去除uncertainty后成功率从100%跌至20%。这说明uncertainty没有浪费capacity去学习平庸场景中的冗余信号,而是在真正ambiguous时提供关键约束。然而必须指出,基座表示SGM本身贡献了绝大部分增益(R2R上72→76 vs 76→78),3DGS的高质量重建可能是性能提升的底层驱动;uncertainty更像是'让已经很好的表示变得更可靠'的增量,而非独立支撑性能的核心。三种uncertainty中,epistemic(几何+语义)贡献大于aleatoric(外观),符合导航任务对结构和语义可靠性的强依赖。
Relation To Prior Work
与3DGS-VLN(同组作者先前工作)的关系最为直接:前者建立了3DGS用于VLN的基线,本文则在其上添加了uncertainty-aware层。与VER(voxel-based)和DUET(topological graph + 2D features)相比,本文的实质差异不在于planner或memory结构(基本延续DUET框架),而在于perception branch从deterministic feature升级为probabilistic value field。与VLN-Copilot等决策层uncertainty工作不同,本文的uncertainty是perception-level且与3D空间同构的。技术谱系上,这属于'显式3D表示 + 贝叶斯深度学习'的交叉:变分推断和Fisher Information在novel view synthesis中已有应用,但本文的创新在于将这些工具适配到Gaussian primitives的物理参数上,并重新定义其语义为导航中的affordance和constraint。真正的新增信息是如何把uncertainty estimation从'渲染质量评估'转化为'导航决策信号'。
Dataset / Evaluation
在Matterport3D仿真器的三个标准benchmark(R2R, RxR, REVERIE)上评估,覆盖细粒度指令、多语言长轨迹和高层远程目标定位,但未涉及真实世界或真机。Benchmark metrics(SR, SPL, nDTW, RGS等)验证了整体性能提升,但幅度 modest(SR通常+1~3%)。真正支撑核心claim——'uncertainty提升ambiguous场景下的可靠性'——的不是主表数字,而是定性case study和Table 14的uncertainty scaling分析:后者显示在复杂场景中uncertainty是necessary condition。Evaluation的局限在于:1) 静态仿真环境无法测试dynamic场景下的uncertainty传播;2) 没有显式的'uncertainty calibration'评估(如预测不确定性与实际错误率是否匹配);3) REVERIE上的RGS提升可能部分来自SGM的细粒度3D语义grounding能力,而非uncertainty-aware planning本身。
Limitation
方法成立的前提是静态、结构化室内环境及可靠的RGB-D输入;一旦面对动态物体或非结构化场景,SGM的增量式构建和Fisher近似都可能失效。性能增益与3DGS基座表示的优越性高度耦合,ablation显示uncertainty单独贡献(74.2% SR)甚至不如SGM单独贡献(76.2% SR),所谓'uncertainty-aware'更像是在强大基座上的锦上添花。Agent缺乏active perception能力,不能主动选择viewpoint来降低epistemic uncertainty,这限制了其在真实开放环境中的自主性。此外,Fisher Information作为外观不确定性的proxy假设渲染残差为零,在真实传感器噪声下该假设的稳健性未被充分验证。训练开销方面,SAM2+CLIP的语义提取和每步SGM构建带来显著latency,虽然可用MobileSAM压缩,但这本质上是精度-效率的trade-off而非解决根本复杂度。
Takeaway
- 1. 显式3D表示的下一个阶段不是更稠密的几何,而是'几何+置信度'的联合场;3D Gaussian的参数可解释性使其成为uncertainty quantification的理想载体。
- 2. Epistemic uncertainty(几何/语义)在embodied decision making中的价值高于aleatoric uncertainty,未来的关键方向是结合active perception来系统性降低前者。
- 3. 将uncertainty编码为scene representation的附加维度(而非决策层标量confidence)是与空间推理自然耦合的设计,可迁移到manipulation、exploration等其他embodied任务。
- 4. 当前仿真benchmark可能不足以区分'更好的重建'和'更好的不确定性建模',领域需要更细粒度的robustness benchmark(如动态遮挡、 adversarial texture)来真正评估uncertainty-aware方法。
一句话总结
这篇论文属于显式3D场景表示与感知不确定性量化的交叉,它利用3D Gaussian参数的物理可解释性将几何/语义/外观不确定性统一编码为空间化的3D Value Map以指导导航,但在静态仿真环境中其性能增益与3DGS基座表示的提升存在显著耦合,uncertainty建模更像是在强基座上的可靠性增量而非独立支撑性能的核心驱动力。