主页
← Embodied AI TopConf Index
+
点赞
0
Embodied AI TopConf · CORL2025
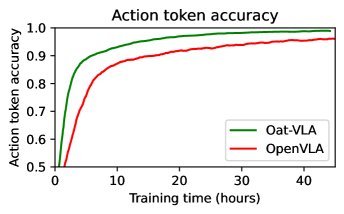
Focusing on What Matters: Object-Agent-centric Tokenization for Vision Language Action models
CORL2025 / Vision-Language-Action Model
视觉语言动作
感知
新标签打开 AlphaXiv
AlphaXiv 中文论文页面(可滚动查看)