精读笔记
Problem Setting
论文实际解决的是无回放的连续视觉语言导航(VLN)中的灾难性遗忘问题。其真正困难在于:VLN是部分可观测下的长程序列决策,需要同时维护全局空间拓扑结构与局部指令-视觉对齐;传统回放缓冲区方案在存储、隐私和计算上不可扩展,而标准正则化方法(如EWC/L2)通过压制参数更新来保护旧知识,严重损害了对新环境的适应能力(plasticity)。该任务的关键矛盾是:在共享参数的密集模型中,适应新域与保留旧域知识存在根本性的参数竞争。
Motivation
已有连续学习(CL)工作多集中在分类或VQA,VLN领域的探索几乎仅限于基于回放的轨迹重放。作者的核心观察是:导航策略天然包含两个不同时间尺度的推理——全局场景结构理解(如办公区与住宅的布局差异)和局部token级感知对齐(如“厨房”一词的细粒度 grounding)。将二者耦合在同一参数空间中会导致“牵一发而动全身”:调整局部感知会干扰全局策略,反之亦然。此外,作者发现MoE框架虽被用于CL(如CL-MoE),但缺乏针对导航任务层次化认知结构的显式建模,导致专家分工模糊、知识隔离不彻底。关键缺口在于:需要一种无需访问旧数据、能自动识别并隔离“该变的参数”与“不该变的参数”的结构化机制。
Core Idea
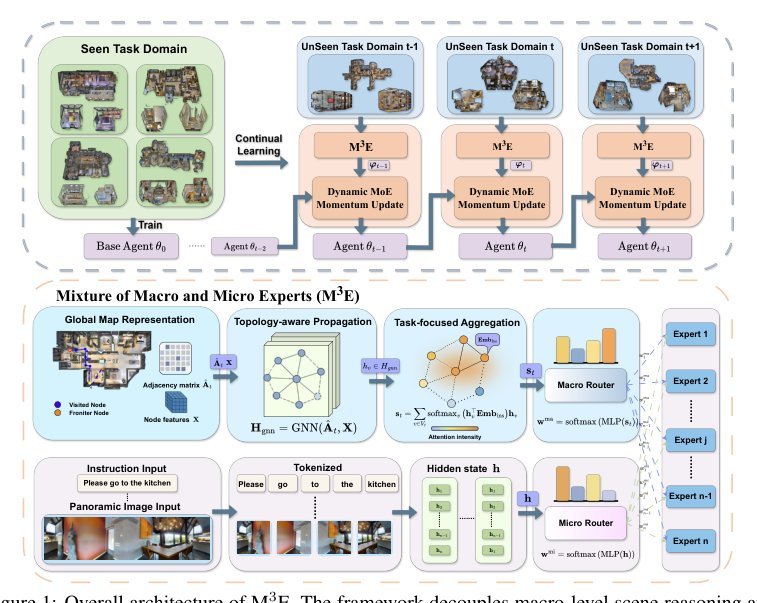
核心思想是通过“层次化双路由”强制解耦导航的全局策略推理与局部语义推理,并利用MoE的天然稀疏性实现参数层面的知识隔离。具体而言,宏观路由(Macro Router)以在线构建的认知地图(cognitive map)为输入,通过GNN传播拓扑关系并用指令嵌入筛选关键节点,输出场景级先验;微观路由(Micro Router)则从LLM隐状态提取token级分布,输出局部语义似然。二者融合后选择MoE-LoRA专家。这一设计引入了一个强归纳偏置:导航不是单层的感知-动作映射,而是“全局语境决定调用何种策略专家、局部语境决定调用何种感知专家”的分层决策。与现有MoE-CL方法的本质区别在于:不是让模型从数据中学习隐含的任务划分,而是显式将空间拓扑与语言token作为两个独立的信息源注入路由,迫使专家在物理上分工。由此,新域主要激活并改写负责场景结构的宏观专家,而负责细粒度grounding的微观专家得以跨域复用,提升了可扩展性。
Method
方法可压缩为三个关键机制。第一,拓扑感知的宏观路由:将已访问节点与前沿节点构造成稀疏图,经GNN消息传递和指令引导的注意力聚合为场景向量,再映射为专家权重。它解决的是“当前处于何种结构性环境”的辨识问题,没有拓扑传播则无法区分跨域复用的布局模式。第二,Token级微观路由:基于LLM每层的hidden state直接生成token-wise routing分布,使不同语义单元(动词vs名词)能激活不同感知专家,解决细粒度指令grounding的局部决策需求。第三,动态动量更新:在训练每个新域时,累积所有token上融合后的路由权重以统计各专家的“任务贡献度”,对Top-K重要专家采用低动量(向新任务快速偏移),其余专家采用高动量(保留旧参数)。它解决的是无回放条件下的知识巩固问题——利用MoE路由统计天然提供的在线参数重要性估计,替代了需要访问旧数据的Fisher信息或需要反向传播约束的正则化。
Key Insight / Why It Works
最核心的是结构化的知识隔离加上基于使用统计的差异化更新。MoE提供了物理隔离,使得domain-specific和domain-general知识不必在同一参数空间中竞争;而动态动量进一步把更新限制在“被当前任务频繁使用的专家”上,相当于自动做了参数选择。消融实验表明三个组件严格互补:仅有动量更新(相当于EMA)时成功率显著下降,说明无专家隔离的密集模型无法平衡稳定与可塑;仅有双路由无动量时遗忘严重(BWT -6.05),说明路由本身不能防止遗忘;三者结合才实现BWT≈0且最高成功率。附录中的专家激活可视化提供了强证据:宏观专家在不同域间激活模式剧烈变化(domain-specific),微观专家则跨域保持稳定(domain-general),验证了设计假设。但需指出,β=0.3的设置意味着模型70%依赖微观路由,宏观GNN更多扮演结构化正则化角色,核心防遗忘能力可能来自动量更新机制本身。
Relation To Prior Work
与基于回放的VLN连续学习方法(PerpR/ESR/Dual-SR)正交,证明不存储原始轨迹也能超越回放策略;与CL-MoE(VQA)最接近,但本质差异在于CL-MoE是单层任务路由,而M3E针对导航的层次化认知结构显式解耦了全局拓扑与局部语义;与测试时自适应(FSTTA/FeedTTA)不同,后者在推断期更新共享参数导致遗忘,M3E则通过架构隔离实现终身记忆。整体属于“LLM-based VLN + 结构化MoE + 无回放CL”的技术谱系,其中真正新增的信息是“将认知地图拓扑作为路由信号”和“基于路由统计的差异化动量”。
Dataset / Evaluation
评估基于R2R与REVERIE的域增量设定,按场景ID将val-unseen划分为约8个连续域。该设定控制了训练预算与数据划分,能比较公平地对比回放与无回放方法,且BWT计算包含BaseAgent,比部分已有工作更严格。然而,benchmark仍停留在离散模拟器与短序列(<10个域)层面,无真实世界或真机实验;每个域的数据量有限,可能高估小范围专家特化的效果。此外,未测试跨benchmark连续迁移(如R2R→REVERIE),难以支撑对真正开放域泛化的claim。
Limitation
方法成立的前提是在线认知地图可被相对准确地构建(simulator中提供完美位姿与离散观测)。虽然文中做了地图噪声的鲁棒性测试,但模拟器中的随机边丢弃与真实世界SLAM误差、视觉域偏移完全不是一回事,Sim-to-Real鸿沟未跨越。可扩展性上限明显:固定6个专家,附录显示增至8个已饱和,在真正开放域终身学习(数百个域)中必然出现专家容量不足,而文中无动态增删机制。评估方面,连续流仅包含约8个域,属于短序列增量学习,未验证长序列下的累积效应;且按场景ID划分域的方式可能让模型依赖低层视觉统计(如纹理/颜色)而非真正的拓扑推理来区分域。增益归因上,β=0.3意味着模型70%依赖微观路由,宏观GNN的引入带来的额外计算与收益比未充分论证,核心增益可能主要来自“MoE-LoRA + usage-based momentum”而非双路由本身。
Takeaway
- 1. 层次化路由是MoE在具身智能任务中的关键进化:不是简单堆叠专家,而是让路由反映任务固有的多时间尺度结构(全局策略vs局部感知),这一思想可向长程机器人操作与任务规划迁移。
- 2. MoE的路由统计是无回放连续学习的天然信号:比基于梯度的参数重要性估计更轻量、更在线,未来可进一步探索专家粒度的生命周期管理(动态增删、合并)。
- 3. 当前VLN连续学习benchmark仍过于“干净”:从8个域的增量到真实终身开放流存在数量级差距,下一步应推动跨数据集、跨视觉域、长序列的更具挑战性的协议。
一句话总结
M3E通过显式解耦全局拓扑推理与局部语义grounding的层次化MoE路由,结合基于专家使用统计的差异化动量更新,在无需数据回放的条件下实现了VLN agent的跨域持续适应,其核心价值在于用架构隔离替代了数据回放来解决遗忘问题。