精读笔记
Problem Setting
它解决的不是一般的 open-vocabulary manipulation,而是“语言驱动的 articulated-object 操作中,语义部件与动作部件不一致”的问题。真正困难在于:同一个人类可指代的 part,可能在机器人视角下对应完全不同的关节类型、运动方式和控制点;反过来,同一种动作原语(按、拉、旋转)也可能落在很多不同语义对象上。以前方法卡在两个地方:一是 part detection 只会告诉你“这是什么”,不会告诉你“怎么动”;二是 language planner 只能给高层目标,缺少稳定的部件级执行接口。关键矛盾就是语义对齐和物理对齐不是同一个空间。
Motivation
作者的出发点是:articulated object 的自然语言交互,瓶颈不在“能不能看见物体”,而在“能不能把人类语义映射到机器人可执行的部件动作”。以前的路线大多只覆盖了单侧能力:要么会做视觉 affordance,但不懂语言;要么会做语言规划,但不会细粒度 part grounding;要么有 part representation,但只在少数类别和单步动作上成立。论文的核心缺口就是缺少一个能同时承接 cognitive affordance 和 physical affordance 的中间层。
Core Idea
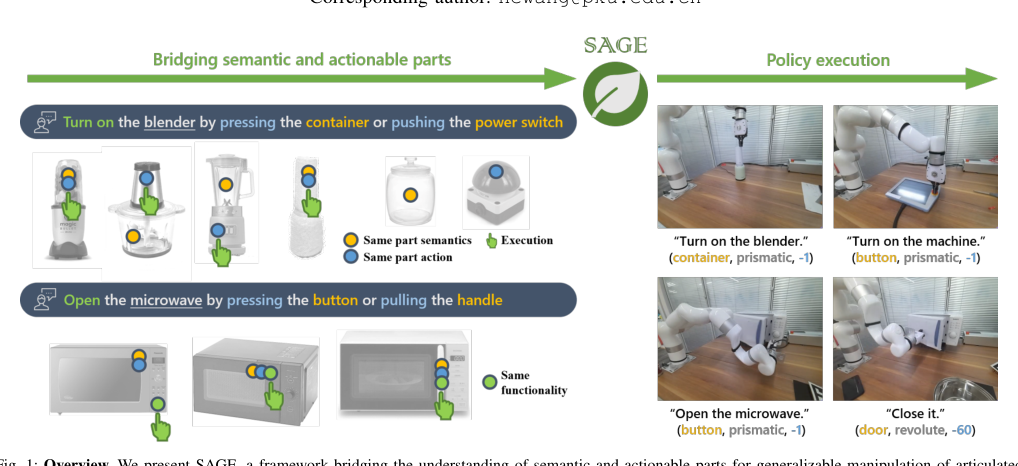
SAGE 的核心思想是:不要直接让模型从图像+语言端到端地产生动作,而是先把 articulated object 的 part 统一拆成“语义层”和“动作层”两个坐标系,再在中间建立一个桥。
语义层负责回答“用户说的是哪一部分”“这个场景里有哪些可交互对象”;动作层负责回答“哪些 part 在物理上属于同一类可执行 affordance”“应该沿什么 joint/state 变化来操作”。论文真正改变的是建模方式:把 manipulation 问题从“对象级 policy learning”改成“part-level translation problem”。这样做的好处是,语言指令只需要对齐到 part 语义,执行再由 GAPart 这种跨类别动作先验承接。直觉上,这比直接学整机策略更可扩展,因为 articulated-object 的长尾差异主要体现在表面语义与机械结构的解耦,而不是每次都要重新学习一套 control policy。
Method
1)先做 part-aware scene perception:不是单独识别物体类别,而是把语义 part、对象状态、交互可能性一起写进场景描述。必要性在于,语言规划需要的是可操作的世界状态,而不是一张普通 caption。
2)把语言转成 action program:用 action unit 把指令显式化为 part name、joint type、state change。必要性在于,长句和复合目标如果不结构化,后续执行只能靠隐式 prompt guessing。这里的核心变化是把自然语言从自由文本变成可组合程序。
3)把语义 part ground 到 GAPart:这是全篇最关键的机制。没有这一步,语义上“像容器”的部件和动作上“要按的按钮”之间就断了;有了这一步,语言指令才能被映射到跨类别可迁移的动作原型。
4)用模板化 trajectory 执行:这一步解决的是低层控制稳定性,而不是学习能力。它的作用是把高层意图转成可重复的操作轨迹,因此更像传统 motion planning 与 part priors 的组合。
5)失败时做交互反馈再规划:这一步的意义不是聪明,而是把系统从纯 open-loop 拉回有限闭环。它主要提升鲁棒性,但并不证明系统拥有更深的因果推理。
Key Insight / Why It Works
这篇论文最值得记住的 insight 是:articulated-object manipulation 的关键泛化单元不是 object category,而是“语义 part × actionability”的对齐关系。这个对齐关系一旦建立,语言指令、视觉理解和控制执行就可以被拆到不同模块里,各自吃自己擅长的信息。
为什么它会有效?第一,VLM 擅长提供开放词汇的语义与上下文,但对 part 级几何/状态常常不准;small expert model 则反过来,能更准确地给出可操作部件和关节状态。两者拼接后,scene description 的噪声会显著下降。第二,GAPart 作为中间表示,把连续、多样的对象结构压缩成少数可复用的动作原型,这本质上是 representation alignment + memory reuse,而不是从零学习控制。第三,interactive feedback 让系统从脆弱的 open-loop 变成有限闭环,至少能处理一部分执行偏差。
但我会直接判断:这篇工作最核心的贡献更像是“更强的 inductive bias + 更强的外部知识注入”,而不是新型学习算法。真正推动性能的,可能是 part/action 的结构化先验、GPT-4V 的强理解能力,以及 GAPartNet 的专家知识;所谓推理和规划,很多时候是把已有知识串起来。
Relation To Prior Work
它最接近的谱系有三条:
第一条是 GAPartNet / PartManip 这一类 part-based manipulation。SAGE 继承了“用 part 作为泛化单元”的思想,但把 part representation 从纯视觉/几何提升到了语言可用的语义-动作桥。实质差异是:以前是为 manipulation 学 part,SAGE 是为 language-guided manipulation 组织 part。
第二条是 VoxPoser / LLM-based planners。它们擅长用大模型做高层决策或 value map 推理,但缺少对 articulated parts 的精细视觉理解。SAGE 的不同点在于,它不把 VLM 当作唯一规划器,而是让它和 domain expert 互补。
第三条是把 VLM 与小模型混合使用的 generalist/specialist 路线。SAGE 真正新增的不是“混合”本身,而是混合发生在 part perception 和 instruction comprehension 两个关键瓶颈上,并且最终通过 GAPart 把这两种信息强制对齐到执行空间。很多看似新颖的部分,其实是已有思想的重组;真正的新增信息是“part-level semantic-action alignment”这个接口。
Dataset / Evaluation
评估上,论文试图覆盖三件事:语言任务执行、part perception、场景描述质量。这个组合比单纯看 success rate 更像是在验证系统链条是否闭合。
优点是它确实包含仿真与真机,也覆盖多个对象类别和多种任务形式,不只是单一的 door opening。尤其它额外做了 scene description 和 part perception 的中间评估,说明作者意识到核心 claim 不在最终成功率,而在中间表示是否真的更好。
但 evaluation 也有明显限制:任务类型仍然主要围绕典型 GAPart 和常见家庭物体,很多任务本质上还是“已知部件 + 已知运动模板”的组合。也就是说,它验证的是跨类别 part-action 对齐,而不是开放世界的未知动作发现。真机部分虽然有说服力,但规模不大,更像 proof-of-concept。
Limitation
最大限制是它并没有真正解决“从语言学习动作”的问题,而是把问题转化成“识别已知 part,再套用已知动作模板”。这意味着它的泛化边界很可能由 GAPartNet 的动作类别和训练覆盖决定,而不是由语言模型的开放世界能力决定。
另一个隐含前提是:场景中的可操作部件必须能被稳定检测到,且其 motion family 能被预定义。只要遇到高度非标准、复合联动、隐蔽机构或需要多阶段交互的对象,系统就可能退化成 heuristic 拼装。
此外,LLM/VLM 在这里承担了“全局规划器”的角色,但它并没有形成真正的长期状态模型;它更像是基于当前描述做有限重规划。换句话说,论文展示的是一种有用的系统架构,但不是强意义上的 autonomous reasoning。最后,成本问题不只是工程瑕疵,而是方法可复制性的硬约束:如果必须依赖 GPT-4V 级 API 才能稳定工作,那它的研究结论就更偏“系统可行性”而不是“可训练算法”。
Takeaway
- 这篇论文最值得迁移的,不是它的具体 prompt 或轨迹模板,而是“把语言操作问题改写成语义 part → action part 的翻译问题”。
- 它提醒我们:面对开放世界操作,真正可复用的泛化单元往往不是 object category,而是可操作部件及其动作原型。
- 这类系统的上限高度依赖外部专家知识与 test-time compute;如果要继续推进,真正值得做的是把这种桥接关系学习化、压缩化,而不是继续堆更大的 VLM。
- 未来更有价值的方向,是让模型直接学会生成可执行的 part-state transition,而不是依赖手工轨迹库。
一句话总结
SAGE 用“语义 part—动作 part”桥接把语言指令驱动的 articulated-object manipulation 从端到端猜动作,改造成基于结构化 part 对齐与专家动作先验的可执行系统。