精读笔记
Problem Setting
这篇论文解决的是一种典型但常被过度简化的协作问题:机器人必须在歧义意图下做动作选择,而动作选择一旦错了,后续轨迹可能直接进入错误分支,导致任务失败或需要重来。真正难点不是 intent 预测本身,而是多模态意图与规划耦合后,错误会沿时间展开并累积。\n\n以前方法的卡点是:要么过分依赖准确预测,面对歧义时过早承诺;要么通过大集合求覆盖,结果把机器人变得过于保守、频繁求助。关键矛盾就是:风险控制和人类负担是对立的,而且在多步交互里这种对立会被放大。
Motivation
已有路线的问题在于,它们往往只关心预测是否覆盖真值,却不关心覆盖以后机器人到底该不该冒险执行。对 HRI 来说,这个缺口很致命,因为“多给几个候选”并不等价于“更安全”——候选集合过大时,机器人要么过度保守,要么在执行端仍然需要硬选。\n\n作者的核心观察是:真正需要被校准的是 autonomy 的触发条件,而不是单纯的 label coverage。换言之,机器人不是因为不知道而失败,而是因为在不确定时没有一个可证地合理的“停下来问人”的规则。RCIP 正是补这个缺口。
Core Idea
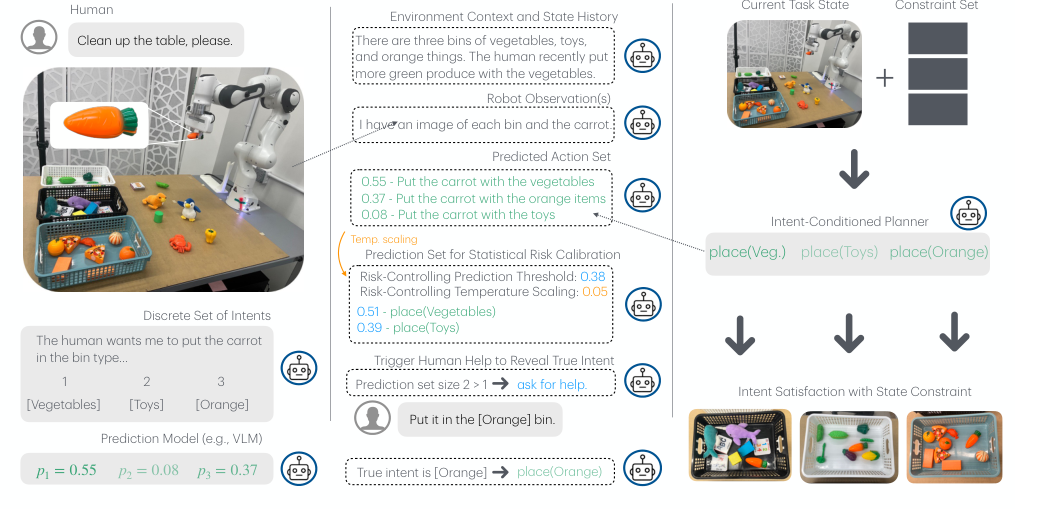
这篇论文把人机协作中的‘不确定意图推理’改写成一个集合决策问题:不是预测唯一意图,而是预测一个足够保守但尽量小的意图/动作集合;只要集合里还有多个互斥行动,机器人就不自作主张,而是触发澄清。这个设计的关键不是保守,而是把保守的触发条件显式地参数化,并用统计校准去调节它。\n\n和传统 predict-then-plan 的本质区别在于,RCIP 不是试图让预测器更 calibrated 后再直接执行,而是把 calibrated set 作为控制接口,让规划器只在“能被集合唯一决定”时才自主执行。这样一来,不确定性不是被平均掉,而是被重新组织成一个可控制的 autonomy gate。
Method
方法的本质是三步:先从冻结的意图预测器里拿到每个意图的置信度;再把高于阈值的意图集合映射成动作集合;最后用‘动作集合是否唯一’决定自主执行还是请求帮助。\n\n为了让这个门槛不是拍脑袋设定,作者在 calibration stage 上把阈值和温度当作低维参数做多重检验,筛选出能满足目标风险预算的参数。多步情况下,他们不再按单步独立看待,而是把整段 rollout 提升到序列级,用最小置信度定义序列分数,再做 causal reconstruction,让在线决策与离线校准对齐。\n\n这个机制的核心变化不是 planner 本身,而是把 planner 变成了‘意图歧义消解器’:planner 负责回答“如果这个意图是真的,能不能执行”,校准层负责回答“当前不确定性下,是否值得让机器人自己决定”。
Key Insight / Why It Works
我认为最核心的 insight 是:把风险控制从‘预测是否正确’改成‘预测集合是否足够单值’,能把 HRI 里最难的那部分不确定性转化成一个可统计控制的门槛问题。这个门槛一旦建立,很多看似复杂的交互逻辑其实都被统一了——当集合塌缩,机器人执行;当集合不塌缩,人类接管。\n\n为什么它可能有效?因为它利用了一个很现实的结构性事实:在很多协作任务里,多个高层意图会映射到相同动作,或者少数几个动作就足以覆盖主要风险。于是与其要求 predictor 输出精确的 intent posterior,不如只关心这个 posterior 在 planner 诱导下是否会产生行动歧义。这里的有效性更像是‘良好的 inductive bias + 风险校准’而非新建模能力。\n\n哪部分最像核心贡献:统计校准框架和多步序列级的风险重述。哪部分更像辅助:具体用 VLM、temperature scaling、softmax 阈值这些实现手段,本质上更多是把现成 predictor 接入框架。也就是说,论文的主要增益来自决策结构,而不是底层模型本身。
Relation To Prior Work
它最接近的谱系是 conformal prediction / empirical risk control + contingency planning,而不是传统 HRI 里那种单纯 intent inference。和普通 conformal 的本质差异在于,RCIP 不满足于控制 label miscoverage,而是把预测集合进一步通过 planner 投影成动作集合,再围绕求助率做二次控制。\n\n和 KnowNo、Simple Set 这类方法相比,RCIP 的新意不在于“也做集合预测”,而在于它把集合预测作为一个可调的 autonomy interface,并显式把帮助率纳入风险预算。和只做轨迹级 contingency planning 的方法相比,它更适合人机协作里高层意图离散、低层动作可由 intent-conditioned planner 生成的场景。\n\n但也要直说:它的很多成分本身并不新,真正新增的是把这些已有想法重新编排成一个可校准的决策门控系统,而不是提出了全新的预测或规划原理。
Dataset / Evaluation
评估覆盖了模拟与真机,而且任务类型不是单一 benchmark,而是跨了多步导航、近距离社交导航、开放类别 sorting、双臂 sorting 等几类典型 HRI 歧义来源。这个覆盖面对论文主张是有帮助的,因为它不是只在一种歧义结构上调参。\n\n但要注意,evaluation 主要验证的是‘在已知任务模板上能否减少求助并维持成功率’,而不是开放世界意图理解。真机实验说明框架可落地,但规模仍然偏小,且很多场景依赖预先定义好的候选意图集合和可执行 planner。换句话说,实验更像是在证明这套校准接口能在若干代表性任务上工作,而不是证明它已经解决了通用 HRI。
Limitation
最硬的限制是,它默认意图是有限离散集合且可被人类明确澄清;这在 sorting、导航这类任务里成立,但一旦进入开放词表偏好、连续目标、或者非语言可解释意图,机制就会明显失效。\n\n第二个限制是,理论保证主要约束的是预测集合层面的风险,不是真实控制闭环中的所有失败模式。文中自己也承认低层执行失败不在保证范围内,所以如果 planner 选对了但控制层出错,RCIP 的统计保证就断了。\n\n第三个限制是,增益归因不够干净。由于 calibration 只在有限网格上搜索阈值和温度,很多提升很可能来自更合适的 decision threshold、数据覆盖和任务模板匹配,而不是框架本身带来的新的推理能力。换句话说,它更像是把已有 predictor/planner 做成了一个风险可控系统,而不是发现了新的协作推理机制。
Takeaway
- 1)在 HRI 里,风险控制对象应该是“何时该问人”,而不是只盯着“预测准不准”。
- \n2)把意图不确定性压缩成动作集合,再用集合是否单值做决策门槛,是一个很强的 inductive bias,尤其适合离散、可澄清、可规划的任务。
- \n3)这篇工作的主要价值是把预测、规划和人类干预统一到一个统计校准框架里;它更像一个可证的自治接口,而不是新的意图理解器。
- \n4)真正可迁移的思想是:把高层不确定性转化成低维可校准的 gate,并把求助视为风险控制的一部分。
一句话总结
RCIP 把人机协作中的意图不确定性从“预测问题”改造成“可统计校准的自治门控问题”,其核心贡献是用集合化意图预测来决定何时该让机器人自主、何时该请求人类澄清。