精读笔记
Problem Setting
这篇论文实际在解决的不是‘机器人要不要发声’,而是‘当机器人必须在真实空间中与人协作时,声音怎样同时承担定位、舒适度和社会归因三种任务’。真正难点在于,这三者常常互相拉扯:越像机器噪音,越容易定位,但越冷;越温和、越角色化,越可能舒适,但又可能损失信息清晰度。以前方法卡在两头:要么只做在线感知评估,离真实在场太远;要么只测单一声学线索,无法说明多维感知是怎么被一起改变的。
Motivation
作者的核心动机不是再做一次证明声音有用的实验,而是补上一个研究生态上的缺口:现有 robot sound literature 太依赖在线 study,缺少对真实互动有效性的确认。另一层动机是,过去工作已经暗示 transformative / emotional sound 可能比简单提示音更能提升 perception,但这种优势是否会在真实场景中被噪音、注意分散、空间定位需求稀释,仍然未知。也就是说,他们想补的是“缺少 in-person replication”和“缺少 localizability 维度”的空白,而不是单纯扩展一个新功能。
Core Idea
论文的核心思想是把机器人声音从单纯的 functional cue 提升为一种可塑造社会角色感的非语言表达层。character-like 声音不是只在关键时刻发声,而是把变换性的连续声学轮廓和情绪化声学轮廓叠加起来,让机器人在动作过程中持续带着某种“性格”被感知。这个设计的本质,不是让机器人多说点信息,而是给人的知觉系统一个更稳定的解释框架:机器人不是只在执行机械动作,而是在以某种有意图的方式行动。与 prior 的本质区别在于,它不把声音当作附属提示,而把声音当作重写机器人社会属性的主通道。
Method
它的方法本质上是一个有控制的 in-person partial replication:保留过去在线研究最关键的声学对比,再把情境搬到真实协作任务中。这样做的必要性在于,robot sound 的效果高度依赖空间、注意力和在场感,纯视频或在线问卷容易高估抽象印象,低估 embodied context 里的噪音、突兀感和定位线索。通过让参与者在协作任务中与机器人共处同一空间,论文把声音的作用从‘看完后评价’转成‘交互时即时感知’,这让它更接近真实部署。机制层面的变化是:评估对象不再只是声音本身,而是声音-动作-空间关系共同构成的感知对象。
Key Insight / Why It Works
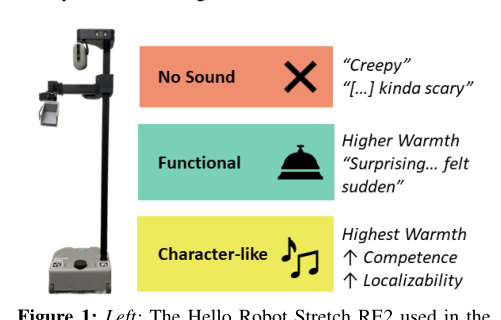
我认为这篇文章最核心的贡献不是“证明声音有效”,而是证明在 in-person 场景里,character-like 声音仍然能稳定地把机器人推向更高的 social warmth,这意味着它背后可能存在一个相当稳的知觉机制:人会把带有连续、节律化、情绪色彩的机器人声音解释为更有主体性、更少机械冷感的行动者。这里真正有效的部分,很可能是 character-like 作为 inductive bias 的作用,而不是某个单独音色本身。它把机器人行为和情绪归因绑定到一起,从而同时影响 warmth 和 localizability。
但这里也要直接下判断:localizability 的提升未必是声音设计本身的高级能力,更可能是因为 character-like 条件用了更持续、更容易被追踪的声学线索;也就是说,这一部分可能更接近感知可追踪性,而不是所谓“角色化表达”的额外价值。functional 声音没有显著复现预期效果,说明简单的提示音在这种任务里不是强机制,甚至可能因为 abrupt、interruptive 而抵消收益。真正稳定的收益,还是来自 character-like 条件对沉默和机械噪音的替代,而不一定来自“功能性编码”本身。
Relation To Prior Work
它最接近的谱系是人机交互里关于 nonverbal robot sound 的一支:从 consequential sound 的被动噪音研究,到 functional sound 的信息提示,再到 transformative/emotional sound 的角色化设计。相较于前者,这篇不是在做新的声学分类,而是在验证一条已有设计假设:更完整的 character-like 声音组合,能比单纯功能提示更稳定地塑造 warmth。真正新增的不是概念,而是把线上发现拉到真实场景中,并引入 localizability 这个在声音研究里常被忽略但很实用的维度。看似新,其实是把已有思想从 survey/video 语境重组到了 embodied replication 语境。
Dataset / Evaluation
这篇工作验证的是一个小样本、单平台、单任务的现实交互场景,因此适合回答“在线结论能否在真实在场互动里复现”,但不足以回答“在什么任务、什么用户、什么机器人上都成立”。评估有一定说服力,因为它包含了量化量表和访谈,且覆盖 warmth、competence、discomfort、localizability、value 等多维感知;但它没有真正测到协作效率、定位准确率或长期使用意愿,所以对核心 claim 的支持主要停留在 perception 层。换句话说,评估能支撑“声音改变感知”,但还不能证明“声音显著改善协作性能”或“这种设计在真实部署中普遍有益”。
Limitation
这篇论文的上限很明显:它验证的是感知层面的短期效应,而不是行为层、长期层或系统层能力。它依赖的前提是参与者愿意把声音当作关于机器人“性格/意图”的线索来解读;一旦任务更紧急、更工业化或用户更熟悉机器人,类似归因未必成立。更重要的是,增益归因并不干净:character-like 条件同时包含 transformative 和 emotional,无法拆解哪个成分在起作用;functional 条件又过于轻量,可能并不能代表“功能性声音”这一路线的上限。再往前说,这项工作很可能主要说明“沉默不好”和“更有设计感的声音更好”,但并没有真正建立可推广的声音设计理论。样本规模和任务覆盖也都限制了外推,核心能力很可能仍然 heavily rely on 小样本主观报告,而不是稳健的跨场景规律。
Takeaway
- 最值得记住的不是“声音能改善机器人形象”这种泛结论,而是:在真实协作里,机器人声音如果只是功能提示,收益有限;但一旦它被设计成具有持续角色感的 character-like 轮廓,就会同时影响温暖感和空间可追踪性。
- 第二个值得迁移的 insight 是,很多机器人交互里的“沉默”并不中性,它会主动生成不安和陌生感。
- 第三个值得迁移的点是,声音设计应该从单一信号思维转向‘感知框架塑形’思维。
- 未来真正值得做的是把这种效应拆解成可复用的声学原则,而不是只在一个任务上重复验证。
一句话总结
这是一次把机器人声音从在线感知结论推进到真实在场复现的工作,其真正贡献在于证明 character-like 声音能稳定提升机器人 warmth,并暗示声音可作为塑造空间可定位性与社会归因的统一通道。