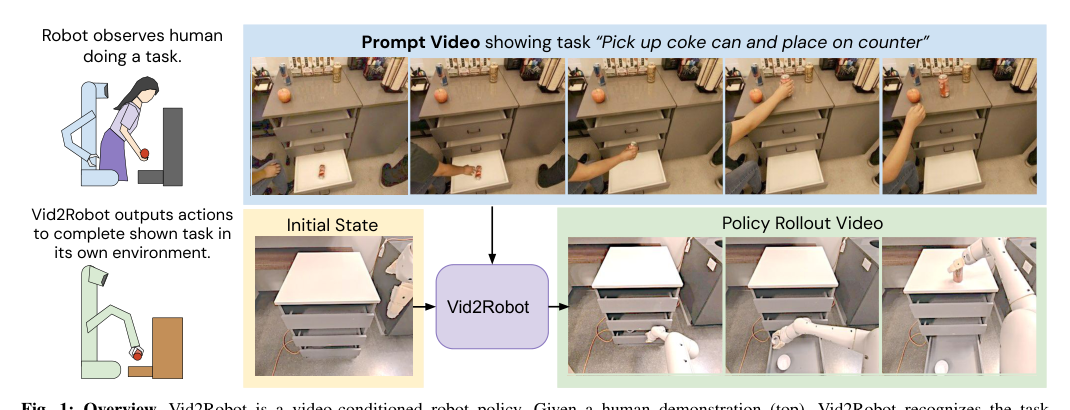
Vid2Robot: End-to-end Video-conditioned Policy Learning with Cross-Attention Transformers
Vidhi Jain, Maria Attarian, Nikhil J Joshi, Ayzaan Wahid, Danny Driess, Quan Vuong, Pannag R Sanketi, Pierre Sermanet, Stefan Welker, Christine Chan, Igor Gilitschenski, Yonatan Bisk, Debidatta Dwibedi · Google DeepMind Robotics;Carnegie Mellon University;University of Toronto