精读笔记
Problem Setting
这篇论文实际在解决的是低样本 visuomotor imitation learning 的泛化问题,尤其是真实机器人部署中的样本效率与安全性冲突。真正困难点不是模仿本身,而是从少量 demonstration 中学到对空间、视角、外观和实例变化都稳的策略。以前 2D diffusion policy 之所以强,是因为动作生成能力好;但它卡在视觉表征上,尤其在数据少、分布变化大的设置里,需要大量 demo 才能覆盖不变性。另一条 3D 路线虽然更有几何感,但常被做成重型 planning / keyframe 体系,速度慢、适配高维控制差,说明问题的关键矛盾是:既要 3D 归纳偏置,又不能牺牲 policy 的实时生成能力。
Motivation
已有路线的问题在于,它们过度相信 2D 视觉表征能通过数据自己学出控制所需的不变性,但真实机器人数据往往不够多,且采集成本太高。作者的观察是,很多失败并不是动作模型不够强,而是视觉条件太弱:同一个任务换个相机角度、换个物体外观,像素空间就变了,policy 需要重新学。关键缺口因此是一个更贴近控制的中间层表征——既要保留 3D 空间信息,又要足够轻、足够鲁棒,不能像重规划系统那样把推理链条拉得太长。
Core Idea
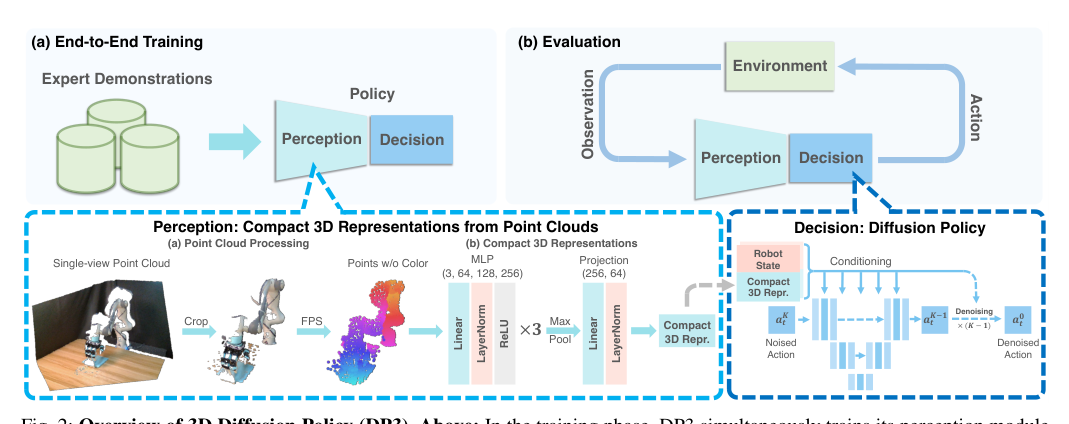
DP3 的核心思想是把“视觉模仿”重新定义成“在一个紧凑的 3D 几何状态上做条件动作生成”。它不是简单把 point cloud 当作另一种输入模态,而是把 3D 作为 policy 的主要归纳偏置:先把单视角深度转成稀疏点云,再压成一个低维 latent,最后让 diffusion policy 在这个 latent 上生成动作序列。这样 policy 的条件不再对相机视角、表面纹理、外观变化高度敏感,而更接近任务的真实物理结构。
本质上,这是一种建模方式的迁移:从“像素到动作”的统计拟合,转向“局部几何关系到动作”的控制拟合。它的潜台词是,很多操控任务并不需要完整 3D 重建,只需要一个足够稳定、与接触和位姿相关的 3D 约束空间。因而它看起来只是换了表征,实际上是在重置 policy 能看到的信息类型。
Method
方法上真正需要关注的是三件事:
- 视觉状态改写:把单视角深度转成点云,并裁剪到与任务相关的空间区域。它解决的是 2D 观测下的视角歧义和背景干扰,核心变化是输入状态更接近机器人实际可操作空间。 - 几何压缩:用轻量 point encoder 将点云压成很小的 latent。它解决的是高维 3D 输入的冗余与不稳定,核心变化是把局部几何关系提炼为可用于控制的紧凑条件。 - 条件动作生成:保留 diffusion policy 作为动作生成 backbone。它解决的是连续动作的多峰性和序列性,核心变化是让 3D latent 只负责“给出物理条件”,而动作细节由生成式策略处理。
这些设计的共同点是:它们都在减少 policy 需要自己学会的东西,把几何先验前置进表示,而不是靠更大模型硬拟合。
Key Insight / Why It Works
我认为这篇论文最强的 insight 不是 diffusion policy,而是把控制条件从 2D 图像压到一个“足够小但足够物理”的 3D latent。它之所以有效,核心原因大概率是 inductive bias,而不是模型容量:
- 3D 点云天然对视角变化更稳,减少了 policy 必须从数据中学习的等变关系。 - 去掉颜色后,policy 被迫关注几何和接触布局,而不是外观捷径,这对跨实例泛化特别关键。 - 裁剪和下采样实际上是在做结构化的注意力,把无关空间排除在外,提升了样本效率。 - diffusion 头则负责处理动作多峰性和序列生成,解决的是“怎么出动作”,而不是“看什么”。
所以,DP3 的主要贡献不是把已有模块拼起来,而是把信息流改造成更适合控制学习的形态。真正值钱的是这个信息瓶颈:让 policy 看到的状态更接近机器人实际可执行、可碰撞约束下的几何状态。另一方面,论文里一些额外增益——比如更快收敛、更少安全违规——很可能是这个表征重构的副产品,而不是 diffusion 本身的独立贡献。
Relation To Prior Work
它最接近两条谱系:一条是 diffusion policy / conditional action generation,另一条是 3D visuomotor policy。和前者相比,DP3 的本质变化不在于动作建模,而在于把条件从 2D 图像换成控制友好的 3D latent;和后者相比,它没有走 keyframe planning、Q-space search 或 heavy 3D transformer 的路线,而是保留了轻量、端到端、实时的 action diffusion 框架。
所以所谓新意,并不在‘用了 diffusion’或‘用了 point cloud’这两个组件本身,而在于它把两者的优点重新组合:3D 负责减少表示歧义,diffusion 负责处理动作分布复杂性。真正新增的信息是:对于短到中等时程操控,正确的瓶颈可能是视觉表征,而不是决策器复杂度。
Dataset / Evaluation
评价的价值主要在覆盖面,而不是单一任务上的漂亮数字。仿真部分横跨多个机器人、物体类型和接触复杂度,既有常规抓取/推送,也有灵巧手、软体、铰接物体和多阶段任务;真实世界则包含灵巧手操作软体、工具接触、以及带随机位置变化的日常物体操作。这个设置至少证明了方法不是只对某个固定 benchmark 调参有效。
但它真正支持的 claim 主要还是“低示范条件下的 generalizable visuomotor policy”,而不是通用机器人学习。评测确实覆盖了空间、视角、外观和实例变化,能支撑作者关于 3D 表征促进泛化的论点;不过任务仍然集中在短到中等时程的操控,缺少需要长期记忆、显式计划或多目标权衡的场景。因此,evaluation 支持的是“3D 表征提高了操控闭环鲁棒性”,不是“解决了泛化机器人学习”。
Limitation
它的上限首先受制于表征本身:point cloud 只保留显式几何,遇到需要材质、细粒度外观、遮挡下的语义推断、或者长时程状态记忆的任务时,这种表示可能不够。其次,作者的真实世界结果虽然强,但任务数量仍少,且场景变化是受控的;因此‘强泛化’更多是局部操作泛化,而不是开放世界泛化。第三,论文里有明显的归因不完全问题:到底是 3D、裁剪、颜色移除、还是轻量 encoder 带来的优势,拆不开。甚至可以说,某些提升可能主要来自更好的数据对齐与更少的输入歧义,而非某种新的决策能力。第四,所谓安全性改善目前更像经验观察,文中未充分说明其机制是否可迁移到更复杂的接触密集任务。
Takeaway
- 1) 对低样本机器人模仿来说,先改表征往往比先改 policy backbone 更划算;DP3 的核心价值就是把控制所需的几何先验前置了。
- 2) 3D 的收益不是自动出现的,关键在于是否把 3D 压缩成一个真正适合控制的 latent,而不是盲目上更重的 3D 模块。
- 3) 这类方法最值得迁移的 insight 是:在物理交互任务里,减少视角/外观歧义比增加模型容量更能提升泛化。
- 4) 但它不是通用规划解法;一旦任务需要长时程记忆、显式推理或复杂目标组合,DP3 这种“几何条件生成”很可能就到头了。
一句话总结
DP3 不是把 diffusion policy 简单升级成 3D 版,而是用一个轻量、几何对齐的 3D 表征重写了 visuomotor 模仿学习的条件空间,从而在少样本操控里显著提升了泛化与部署稳定性。