精读笔记
Problem Setting
它解决的是解释式端到端驾驶在跨域条件下的可泛化问题,而不是单纯的 caption 或 control 回归。困难不在模型能不能拟合训练集,而在于部署时遇到陌生道路、天气、城市或叙述风格时,解释和控制都会同时漂移。以前方法的瓶颈是:specialist 模型需要手工设计的监督和结构,generalist MLLM 又高度依赖大规模指令微调,二者都无法很好处理新域样本。这个任务的关键矛盾是:驾驶解释必须既忠实于当前决策,又要能覆盖长尾场景,但传统训练范式恰恰最怕长尾和域转移。
Motivation
已有路线的问题不是缺少一个更大的 backbone,而是缺少一个能在部署时持续适应新场景的推理接口。作者的核心观察是:驾驶场景里很多知识并不需要永久写进参数,完全可以像案例库一样被检索出来;而且对于解释任务,‘给出相似案例再回答’比‘凭空生成解释’更稳定。这个思路直接对应现实缺口:annotation 太贵、域移太重、重训太慢,所以最合理的方向不是继续堆监督,而是把推理转成检索增强的局部上下文化。
Core Idea
它把驾驶解释/控制从“靠模型参数记忆”改成“靠检索到的驾驶案例进行类比推理”。这不是简单的 RAG 套壳,而是把驾驶任务重新表述为:当前场景应当先找到一组与之在决策模式上相近的历史样例,再让大模型在这些样例的上下文中完成解释和控制预测。这样做的关键好处是,模型不必在参数里压缩所有驾驶情形;它只需要学会如何读取类似案例并在当前样本上做局部适配。理论上,这比纯 fine-tuning 更可扩展,因为新域知识可以通过更新记忆库而不是重训模型来注入。
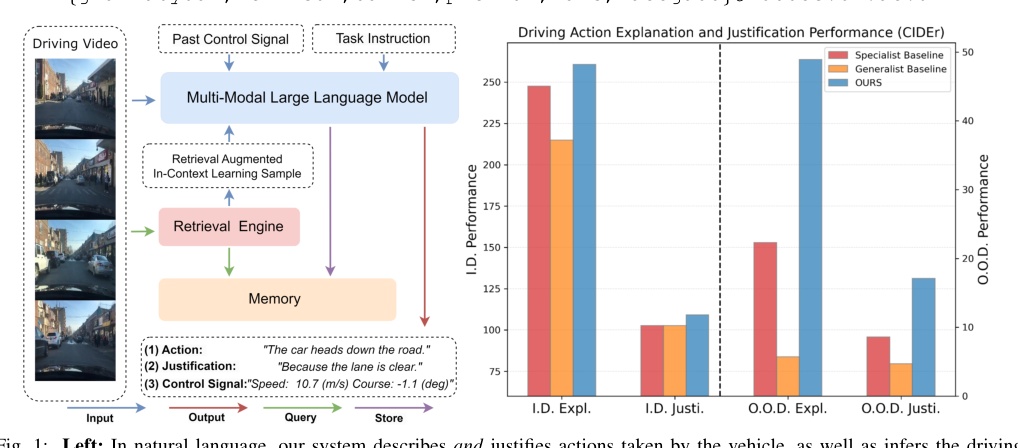
Method
关键机制只有三层:第一层是把视频和文本对齐到同一个 MLLM 空间,确保驾驶片段能被语言模型消费;第二层是用混合表示做检索,把当前场景映射到历史经验中的相似决策片段;第三层是把检索到的样例作为 ICL 前缀,让模型在上下文中同时输出解释、理由和控制信号。这里真正必要的是第二层,因为它决定了模型到底在模仿什么样的演示;第一层和第三层更多是在把这个想法变成可执行的 MLLM 接口。
Key Insight / Why It Works
真正起作用的,不是 MLLM 本身突然变得更聪明,而是检索把它的推理条件变得更“局部”和“有锚点”了。驾驶解释本来就高度依赖场景上下文:同样是减速,原因可能是前车、红灯、弯道、行人、限速变化。把相似场景的动作-理由-控制作为上下文示范,相当于给模型一个低方差的决策先验,减少它在新场景里自由胡说的空间。换句话说,这里的提升更像是 inductive bias 改善 + memory reuse,而不是纯粹的参数知识增长。文中自己也间接印证了这一点:只按视觉相似检索不够,说明真正需要的是“决策相似性”,即要检索到能够示范 reasoning process 的样例。
Relation To Prior Work
它最接近两条谱系:一条是驾驶解释模型(如 BDD-X/ADAPT 一类),另一条是通用 MLLM/ICL/RAG。和前者相比,它不再把解释视为一个固定 decoder 的监督生成问题,而是把解释当作可检索示范支持下的条件生成;和后者相比,它又不是泛泛地给模型外接一个知识库,而是把检索目标设计成驾驶决策相似性,并把控制信号也纳入同一个上下文机制。真正的新意不在“用了 RAG”,而在于把 RAG 的 retrieval 对象从文本知识改成了驾驶案例,并且让 retrieval 直接服务于 reasoning process,而不是只服务于事实补充。
Dataset / Evaluation
评价覆盖了两个层面:BDD-X 上的 in-distribution 解释/控制,以及 Spoken-SAX 上的跨域 zero-shot。前者证明它能和现有 SOTA 竞争,后者才对应论文真正想讲的 generalization claim。这个设置的优点是把“会不会说”和“会不会控”一起看了,不是只做 caption 生成。但问题也很明显:评价仍然是离线的、基于短视频片段的 open-loop 指标,不能证明它在真实闭环驾驶中就更安全;Spoken-SAX 的域差虽然存在,但它更像数据集迁移而不是严格意义上的开放世界部署。
Limitation
它的上限很可能由检索库决定,而不是由语言模型决定。也就是说,这不是一个真正意义上的通用驾驶大模型,而是一个依赖经验库覆盖度的检索系统:库里没有的场景,模型仍然会失真。第二,这种方法把很多能力外包给 memory 和 demonstration,容易让人误以为模型学会了推理,但实际上可能只是做了更好的 pattern matching。第三,论文自己也承认 context window 限制,导致只能放少量 ICL 样例,这直接限制了检索上下文的表达力;如果只放两个示例,很多复杂交互根本讲不全。第四,闭环验证缺失意味着它证明的是“更会解释、更像人类文本”,而不是“更会开车”。
Takeaway
- 第一,这篇工作的真正价值在于把驾驶解释的泛化问题,转化成可检索经验支持的 test-time adaptation 问题。
- 第二,它最值得迁移的 insight 不是某个网络结构,而是:在强上下文依赖任务里,先检索“相似决策过程”往往比检索“相似外观”更重要。
- 第三,它也提醒我们,很多所谓的 MLLM 推理提升,本质上可能来自 memory、demo 和局部条件化,而不是参数化智能本身。
- 第四,未来真正该做的是更大规模、更真实、更闭环的经验记忆与检索策略,而不是继续把解释模型做成更大的黑盒。
一句话总结
RAG-Driver 本质上是把解释式驾驶从“训练一个会说会控的大模型”改写为“用检索到的相似驾驶案例做上下文推理的记忆型驾驶系统”,其核心贡献是 test-time 侧的类比泛化,而不是模型参数侧的能力突破。