精读笔记
Problem Setting
它实际在解决的不是一般意义上的 sim2real,而是低数据条件下的视觉模仿学习迁移:目标域 real 数据很少,源域 sim 数据很多,但两域视觉差足够大以至于直接迁移失败。真正困难点是,sim 数据并不是天然有用的,只有在‘表征对齐’成立时才会成为 real 的归纳偏置;否则它只是额外噪声。以前方法卡住的地方,就是不管是图像层对齐还是随机化,都没能稳定把跨域视觉差转成控制上可复用的结构。
Motivation
已有路线不够,是因为它们都在错误的层面上处理域差:域随机化是在输入分布上做覆盖,但容易变成保守策略;系统辨识是在仿真参数上做拟合,但工程成本高且未必能补齐视觉鸿沟;通用 VLM 则把表示学得太对象中心,缺少机器人控制需要的细粒度空间关系。作者的核心观察是,语言比像素更接近“任务语义状态”,而任务语义状态恰好是 sim 和 real 中最值得共享的部分。缺口在于:缺一个能把语义相似性变成控制可用表示的中间监督。
Core Idea
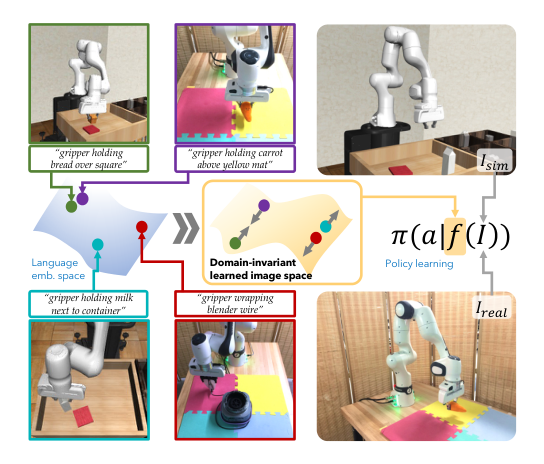
论文真正的想法不是“用语言辅助机器人”,而是把语言当作跨域 representation alignment 的桥。它假设:如果 sim 和 real 图像在语言描述上相近,那么它们对应的任务语义、局部状态和可执行动作也应接近;于是先用语言监督把图像编码器塑造成一个 domain-invariant 的中间空间,再在这个空间里训练 imitation policy。这样做的本质变化是:从‘直接学习 pixels→actions’转成‘先学习 semantics-aligned latent,再学 latent→actions’。这个 latent 空间不是为了泛化到互联网图像,而是为了在当前任务分布内,把 sim 和 real 的动作先验放到同一坐标系里。
Method
机制上分两步:先 pretrain 表征,再在该表征上学 policy。第一步要解决的是域差导致的表征不可比,因此用图像-语言对齐来学习一个跨域共享的 latent;这里的必要性在于,若不先把 sim/real 对齐,后面的 BC 会被 domain shift 拖垮。第二步要解决的是少样本 real 动作监督不足,因此冻结大部分视觉 backbone,只让 policy 在这个已对齐空间中吸收 sim 大数据和少量 real 数据。核心变化不是网络堆叠,而是把学习顺序改成“先语义对齐、后动作拟合”。
Key Insight / Why It Works
我认为这篇工作最关键的贡献是“把跨域对齐从像素层/风格层提升到语义阶段层”,这比单纯视觉预训练更贴近控制。为什么有效?因为在 manipulation 里,动作决策真正依赖的通常不是对象全局类别,而是局部关系状态:距离、接触、朝向、是否 grasp、是否对齐到容器上方等。语言模板恰好能稳定编码这些局部关系,并且这些关系在 sim 和 real 里往往比像素更保守。也就是说,它利用语言把高维视觉差压缩成控制相关的低维结构,从而让 sim 数据成为 real policy 的有效先验。\n\n但我不认为它的增益主要来自“语言理解”本身,更像是更好的 inductive bias + 数据组织方式:语言监督提供了一个比 CLIP/R3M 更贴近机器人阶段变化的对齐目标;自动分段和模板标注又等于给了模型一个阶段化 curriculum;多任务联合训练进一步扩大了 state-action coverage。这里真正的核心可能是 representation alignment 和 data coverage 的叠加,而不是某种新型推理能力。若要更苛刻地说,这更像是为少样本 sim2real 找到了一种更合适的 supervision shaping,而不是发明了新的控制范式。
Relation To Prior Work
它最接近的谱系有三条:一是 vision-language pretraining(CLIP/R3M 一类),二是 domain adaptation / domain invariance,三是 sim2real 的域随机化与系统辨识。真正不同的是,它不是把语言当 task instruction,也不是把语言当通用表征预训练目标,而是把语言直接用作跨域 scene alignment 的监督。相较于 CLIP/R3M,它更任务定制、更控制导向;相较于 domain adaptation,它不在 pixel space 做映射,而是在低维 latent 中做语义一致性约束;相较于传统 sim2real,它避开了对物理精确匹配的依赖。实质创新在于:语言第一次被用来做 sim-real 视觉桥接,而不是只做多模态理解或指令条件控制。
Dataset / Evaluation
评估不是单一 toy setting,而是跨了几个有明显 domain gap 的 manipulation 族:短程堆叠、长程多步 pick-and-place、以及 hard-to-simulate 的 deformable / wrap 类任务,并且在 sim2sim 和真机少样本两种环境都测了。这个设计对论文主张是基本对口的:它验证的是‘语言是否能作为跨域中间表征’。但 evaluation 也有边界:任务虽然多样,仍然都属于同构的分段式操作;成功标准偏执行级,不太能证明更强的规划或组合泛化。换句话说,它验证了跨域控制表征,而不是开放式机器人智能。
Limitation
这篇方法成立非常依赖模板语言和任务分段。只要场景描述无法稳定覆盖 sim/real 的对应关系,或者阶段粒度过粗,语言监督就会变成噪声,甚至把表示压塌成过于抽象的对象级空间。论文自己也承认这点:它不追求互联网预训练那种 general-purpose 表示,而是针对一个特定目标分布做 low-data adaptation。\n\n更重要的是,增益归因并不完全干净。自动语言标注、阶段切分、多任务 sim 数据、以及少量 real 数据共同作用,很难说最终收益到底有多少是真正来自“语言”,有多少只是更好的数据覆盖和更强的 inductive bias。所谓 sim2real bridge,很可能部分是把问题转化成了“在一个更可对齐的 latent 上做多任务 BC”,而不是从根本上解决了域差。对于更复杂的接触-rich、连续动态、长时序规划任务,方法的上限会更明显。
Takeaway
- 这篇论文最值得迁移的 insight 是:当域差太大时,不要直接逼 policy 跨域泛化,而应先找到一个能稳定表达“控制相关语义状态”的中间监督,把跨域对齐做在 latent 层。
- 第二个可迁移点是,少样本 sim2real 很可能需要阶段化、可自动生成的 supervision,而不是依赖昂贵人工标注。
- 第三个判断是,语言在这里不是为了开放词表能力,而是作为一种结构化的、可压缩的语义锚点;未来如果能把这种锚点和时序、接触、几何约束结合,才可能从‘更好的迁移’走向‘更强的 manipulation 表示学习’。
一句话总结
这是一篇把语言从“任务指令”改造成“跨域语义对齐工具”的 sim2real 论文:它的真正贡献不是会说话,而是用语言把 sim 和 real 的控制表征拉到同一空间里,从而让少样本真机模仿学习变得可行。