精读笔记
Problem Setting
它实际在解决的是generalist robot policy里最难的一个耦合问题:如何让视觉-语言模型学到能跨视角、跨本体、跨环境复用的3D空间知识,并把这种知识稳定映射到动作上。真正困难点在于,机器人数据天然是异构的:视觉上不对齐,动作上不共享尺度,导致模型很难像人一样形成一个统一的‘空间工作台’表示。
以前方法卡在两处:一是观测大多停留在2D语义特征,几何信息弱;二是动作输出要么太粗,要么是统一离散化,无法适配不同机器人。关键矛盾就是:你想要跨机器人泛化,但机器人本身的空间坐标和控制语义并不共享。
Motivation
作者的核心观察可以概括成一句:机器人操作的瓶颈不是识别,而是空间建模。以前VLA大多默认2D感知足够,动作也被粗暴离散成统一bins,这种做法隐含了一个不成立的假设——不同机器人在空间上是可直接比较的。但实际不是:摄像机位置不同、工作空间不同、控制器动力学不同,都会让“同一个动作token”在不同机器人上语义漂移。
因此,作者想补的不是“更多参数”而是“缺失的空间坐标系”和“缺失的动作分辨率”。这也是为什么他们会同时改观测和动作:只改一边没法解除空间表征的不一致。
Core Idea
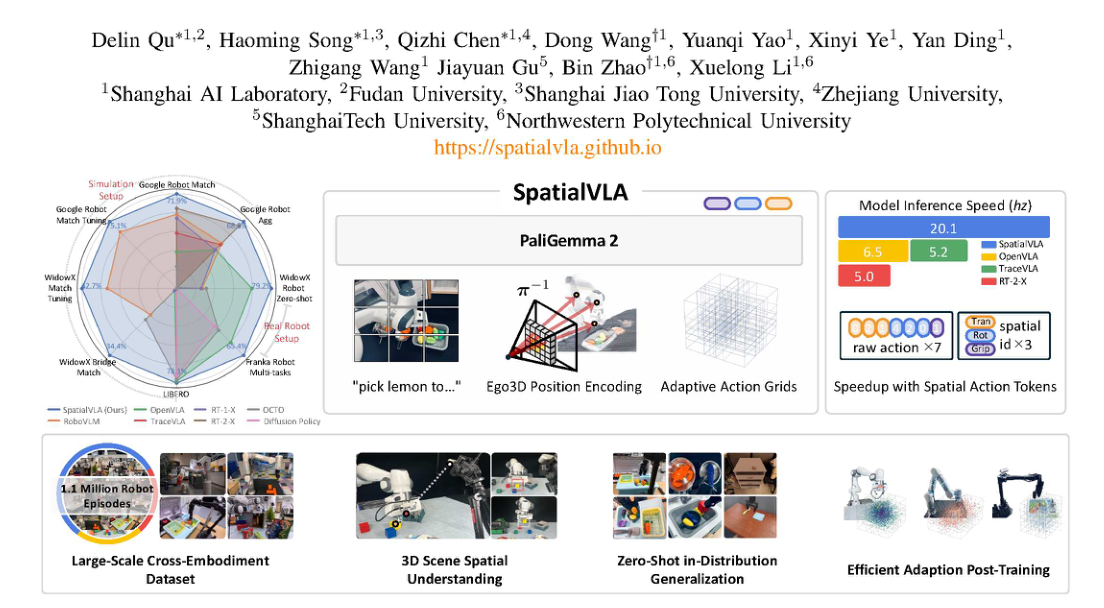
这篇论文的核心不是“又加了一个位置编码/动作头”,而是把VLA重新改造成一个空间对齐系统:输入侧用egocentric 3D位置信息把图像特征锚定到操作者自身坐标系,输出侧用自适应空间网格把连续动作锚定到机器人工作空间中的离散区域。这样做的本质收益是:模型学到的不是视角特定的像素关联,也不是纯标量动作回归,而是空间关系到动作的稳定映射。
这和很多“更强backbone + 更大数据”的路线不同。它引入的是明确的空间归纳偏置:把空间结构从隐变量变成显变量,让模型更容易复用“接近、绕开、对准、伸向某区域”这类跨任务共性的动作原语。直觉上,这会比纯2D token更可迁移,因为操作任务里最稳定的规律往往是空间几何,而不是表面语义。
Method
方法上最关键的是两层空间离散:观测端把单张/少量视图映射到egocentric 3D位置编码,目的在于消除不同相机安装方式造成的空间错位;动作端把连续控制变量改写为自适应网格token,目的在于让动作空间的粒度适应机器人本体和任务分布。
再往下的意义在于预训练与后训练共享同一套空间词表思路:预训练阶段学的是跨任务、跨环境的通用空间动作语义;微调时则通过对新数据分布重新分桶,把旧的空间知识对齐到新机器人。机制上它解决的是“知识如何跨本体复用”而不是单纯“怎么拟合更低的loss”。
Key Insight / Why It Works
我认为最核心的贡献是“空间表征对齐”而不是“token化”本身。Ego3D 让视觉特征不再只依赖相机视角的2D相关性,而是直接带上操作者坐标系里的几何位置;自适应动作网格则让动作头不再学一个对所有机器人都一样的粗糙离散空间,而是学习与数据分布、工作空间、控制尺度相匹配的空间分辨率。两者合起来,相当于把输入-输出之间的映射从高熵的跨本体对应,压缩成一个更规则的空间函数。
为什么有效?因为 manipulation 里很多看似“推理”的部分,本质是几何对齐和局部轨迹生成。只要你把几何结构显式喂进去,模型就更容易把语言指令落到空间动作上。尤其在 cross-robot 场景中,统一的语义不如统一的空间坐标系重要。这里的关键不是语言更强,而是空间更对。
Relation To Prior Work
它最接近的谱系是RT-2/OpenVLA这类把VLM扩展成动作生成器的路线,但与它们相比,SpatialVLA不是只做动作tokenization,而是把‘空间’显式提升为一等公民。和3D-VLA、LLaVA-3D这类增强3D感知的工作相比,它不是只增强看,而是同时重构看和做之间的接口。
和Octo、RDT、HPT这些generalist policy相比,差异不在“更大数据/更多本体”本身,而在表示方式:它不是把异构性主要交给统一架构去吞,而是通过空间对齐把异构性压缩掉。真正的新东西是把空间作为跨本体共享表征,而不是把本体差异留给后验适配。
Dataset / Evaluation
评测覆盖面比较广,至少不是只在单一仿真里自嗨:有真实机器人、有多个环境、有跨视角/纹理/光照变化、有未见物体和新机器人设置,也有专门挑空间布局变化的任务。这个评测设计基本能支撑它的主张:它不是只在普通模仿任务上涨点,而是在“空间变化导致失败”的场景里体现优势。
但也要直说:评测仍然更偏操作基准和局部控制,验证的是空间对齐后短中程操控的鲁棒性,而不是更强的通用规划或开放世界推理。它证明了 spatial representation 有用,但还不足以证明模型真的掌握了更高层次的空间理解。
Limitation
最大的限制是它的“空间统一”仍然是通过离散化和统计重分桶实现的,而不是连续世界模型。因此它的泛化上限很可能受动作分布覆盖限制:只要目标动作落在训练网格和示例轨迹附近,效果会很好;一旦需要明显超出数据支持域的轨迹生成,模型大概率仍会退化。换句话说,它更像把模仿学习做得更空间化,而不是把真正的机器人决策问题解决了。
另外,论文里对“为什么是 Ego3D、为什么是这种网格分辨率、为什么重离散化能稳定迁移”的解释还不够充分,很多收益可能是 representation alignment + data coverage + better discretization 的合成效应,增益归因并不完全干净。
Takeaway
- 1) 这篇论文最值得迁移的 insight 是:在机器人泛化里,空间坐标系比语义标签更基础,尤其对跨视角和跨本体控制。
- 2) 动作离散化不是一个纯工程 trick;如果离散边界由数据分布和工作空间结构决定,它可以变成有效的归纳偏置。
- 3) 真正有潜力的方向不是继续堆 VLM,而是把“空间对齐”做成一个统一接口,连观察、动作、适配都围绕它组织。
- 4) 但要警惕:它证明的是更好的空间模仿,不一定是更强的空间推理。
一句话总结
SpatialVLA 的本质是把 VLA 从“2D 语义驱动的动作生成”改造成“egocentric 3D 对齐的空间模仿系统”,核心贡献在于用空间归纳偏置提升了跨本体、跨场景的操作泛化,而不只是扩大模型或数据。