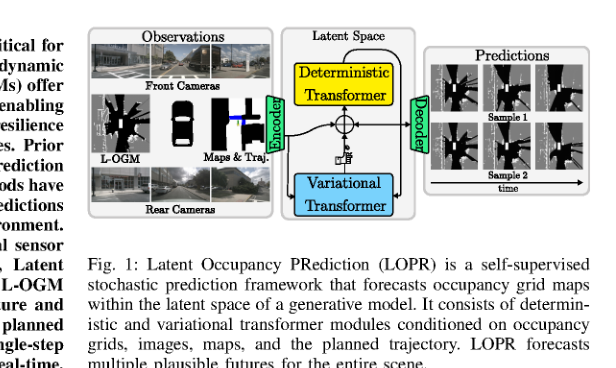
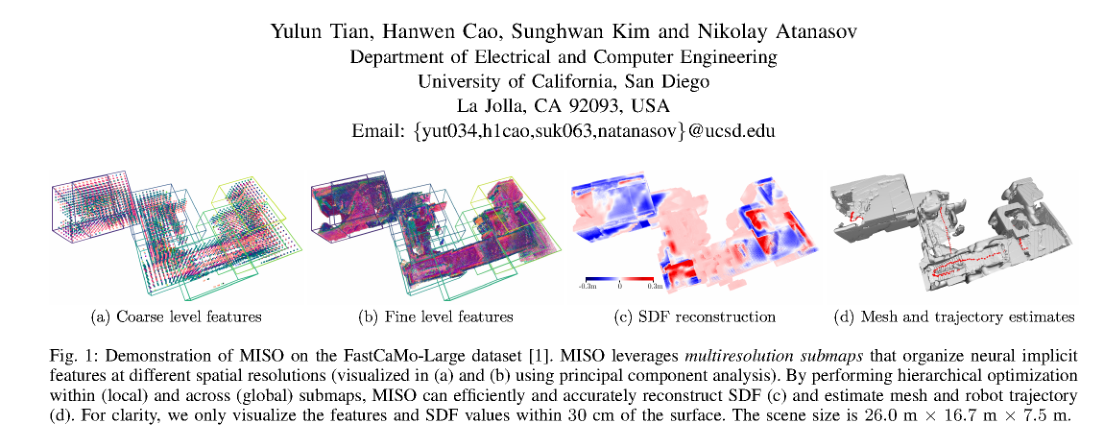
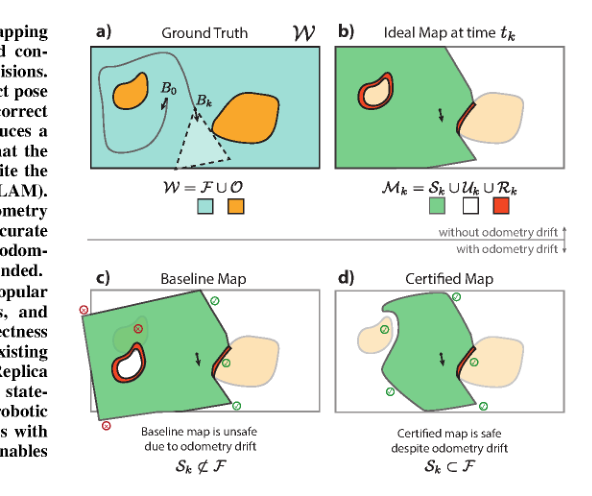
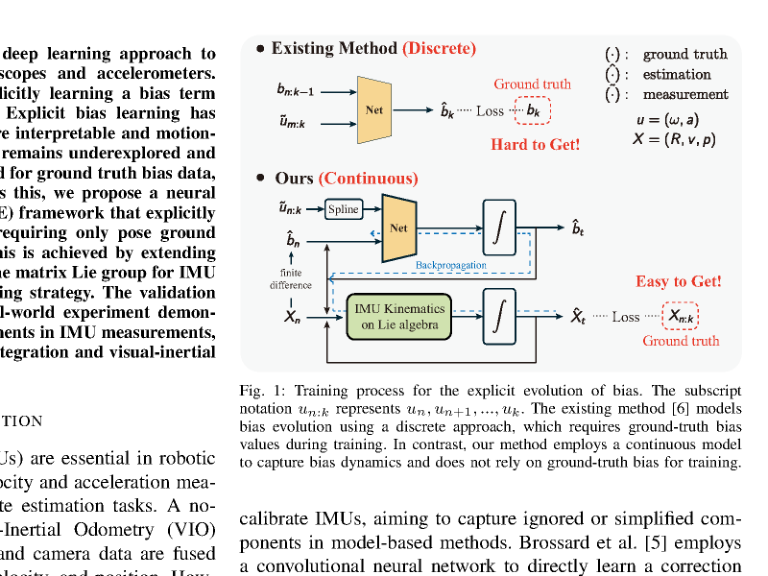
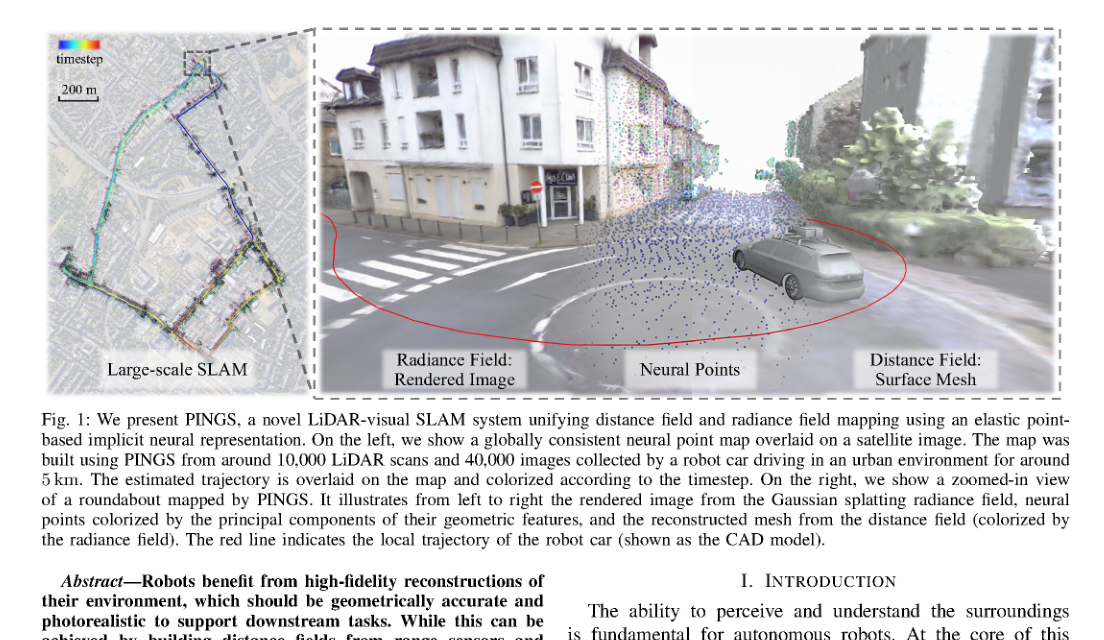
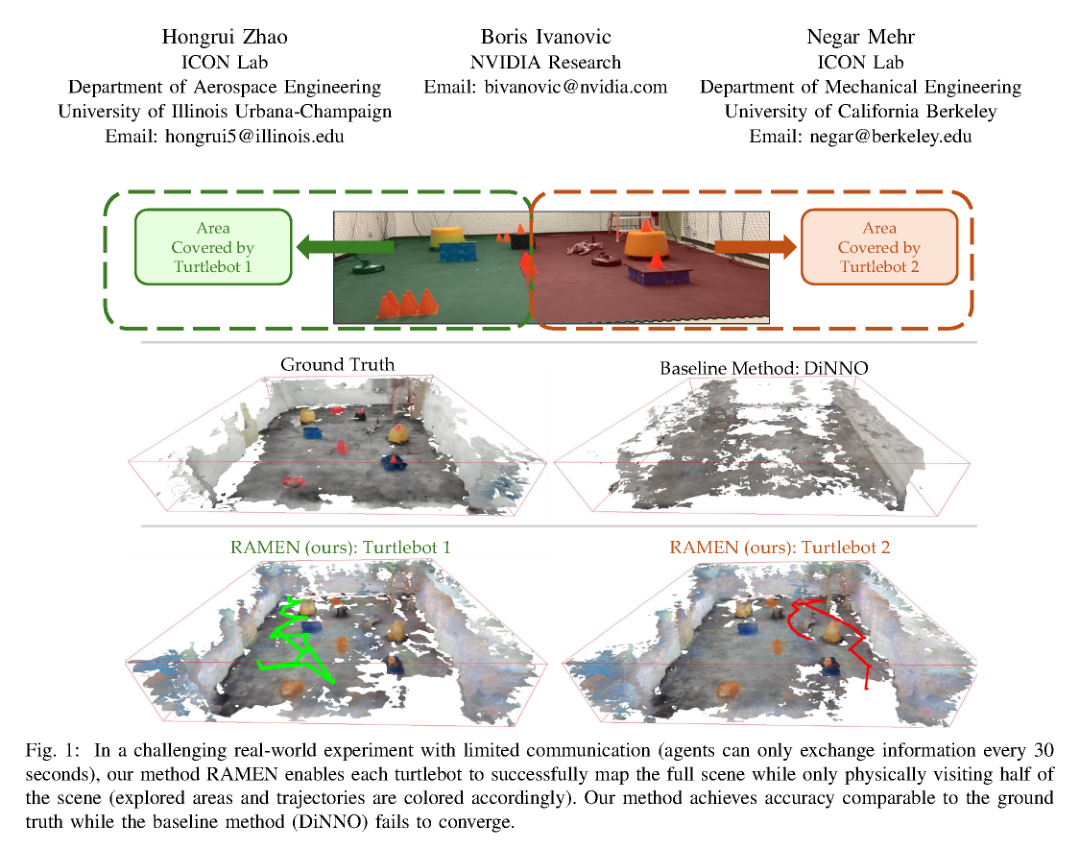
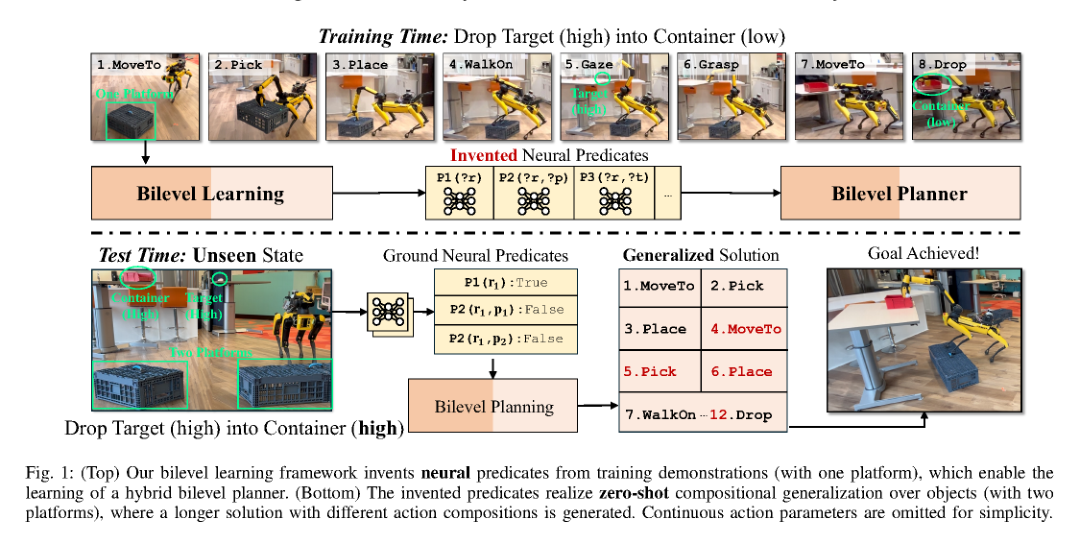
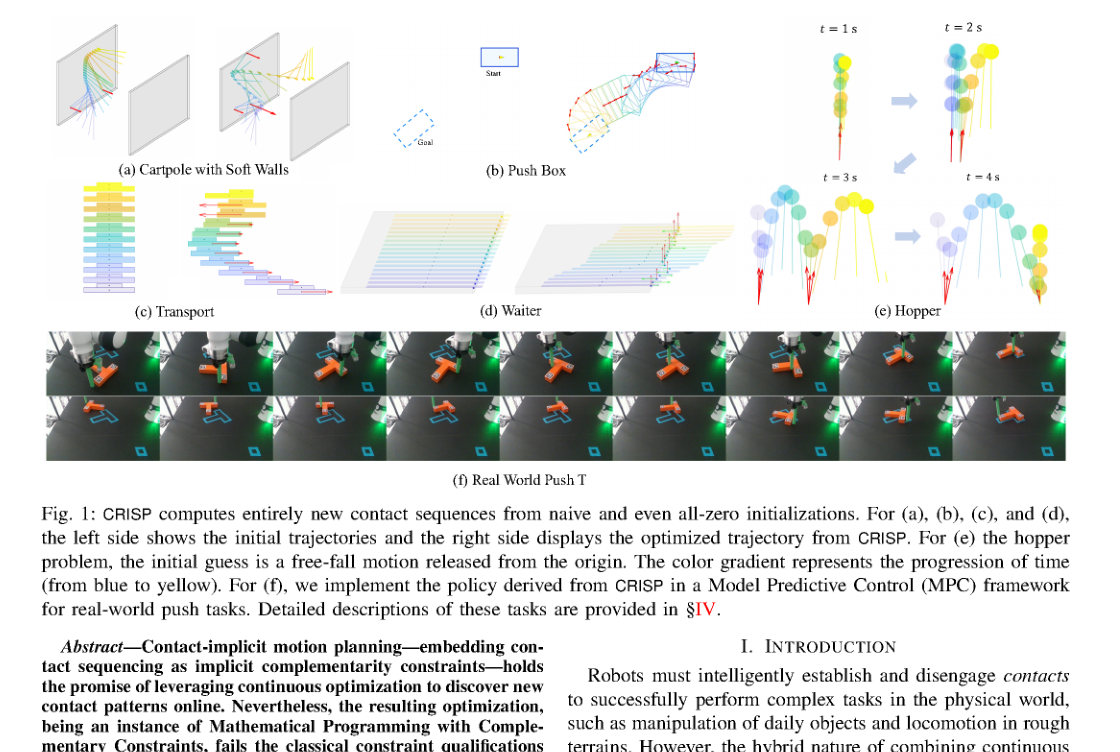
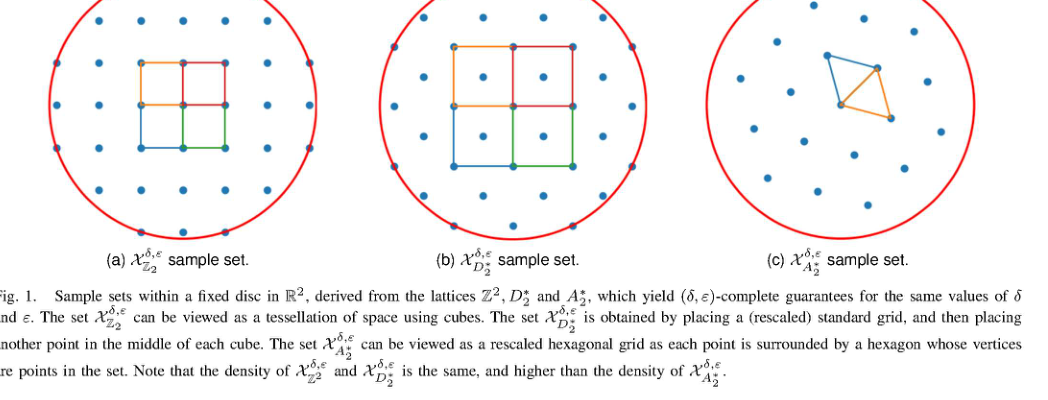
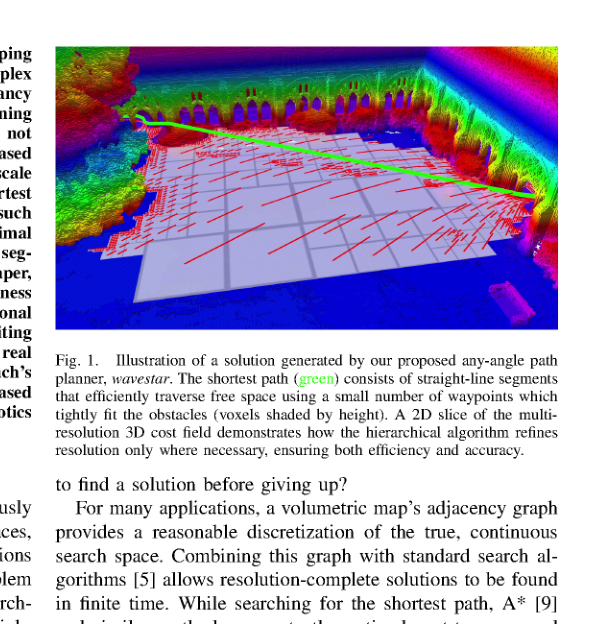
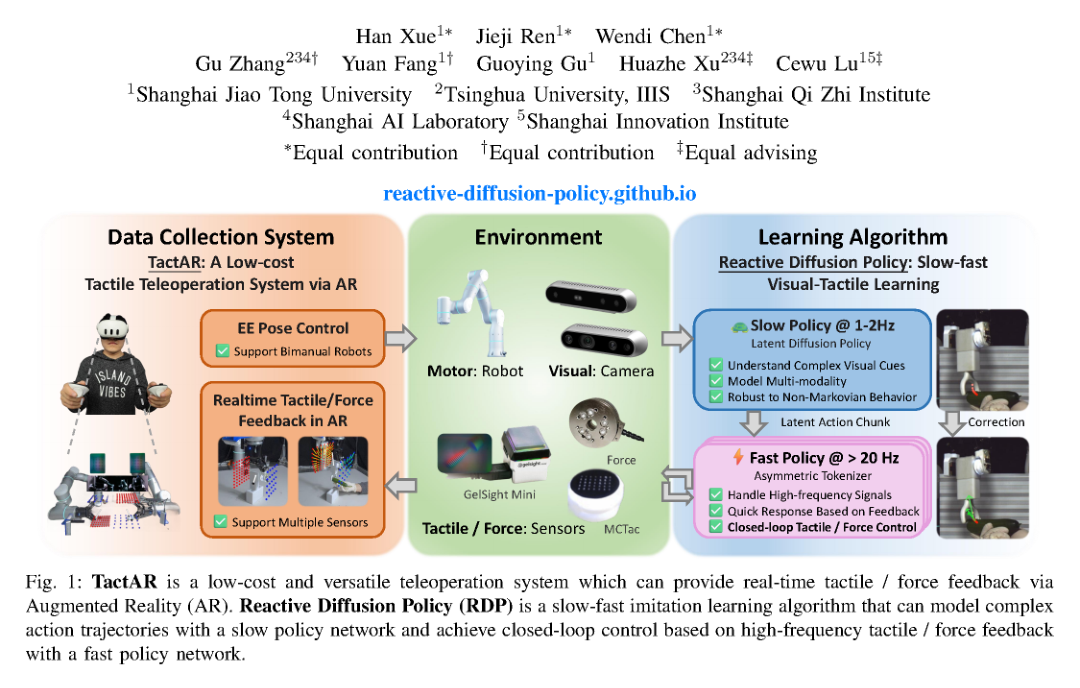
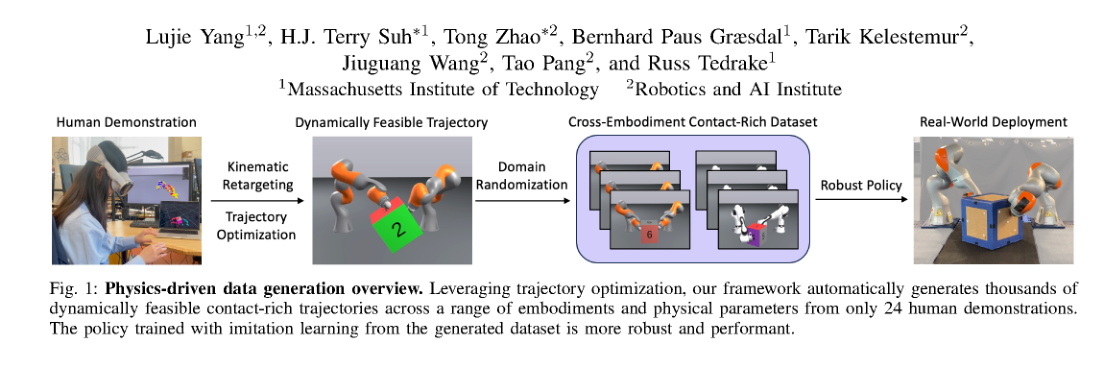
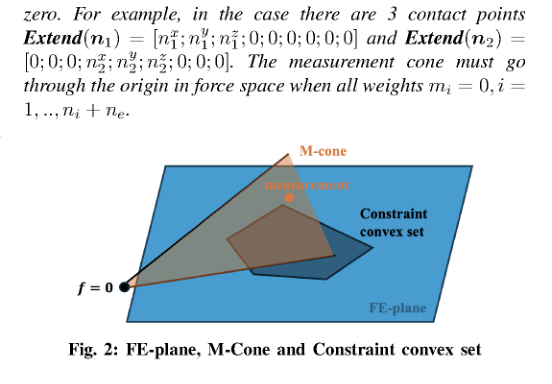
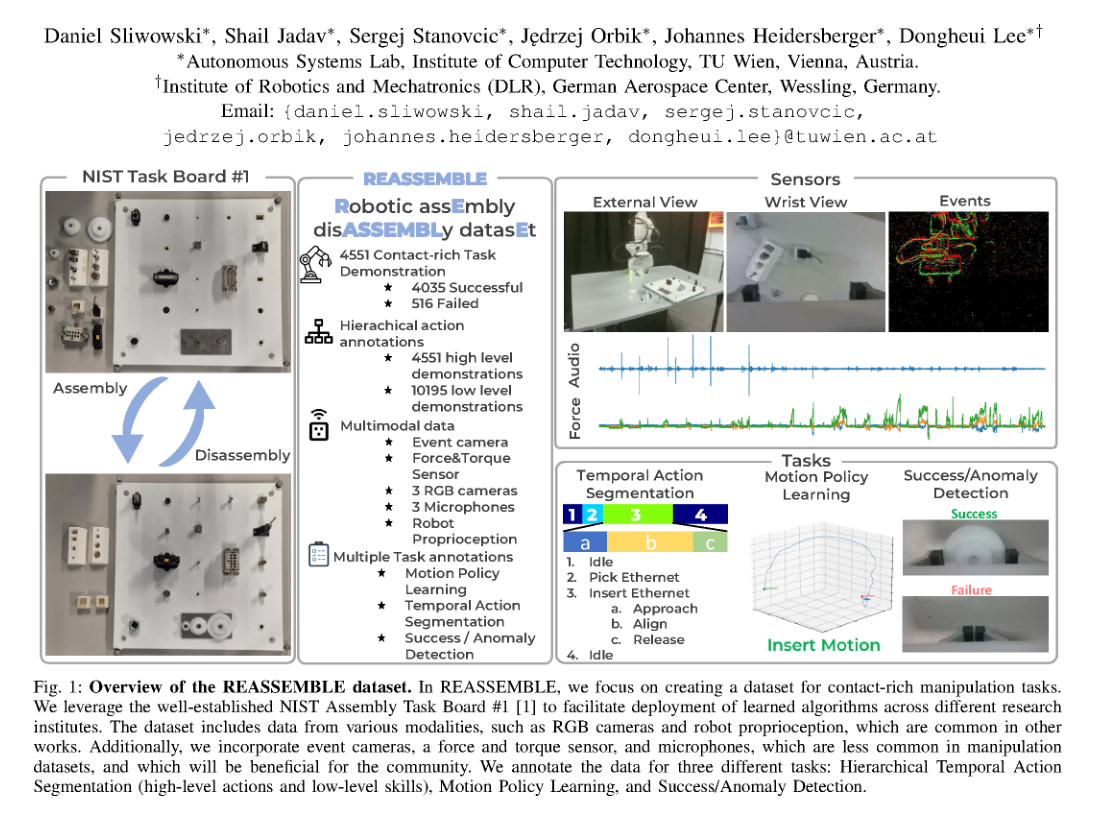
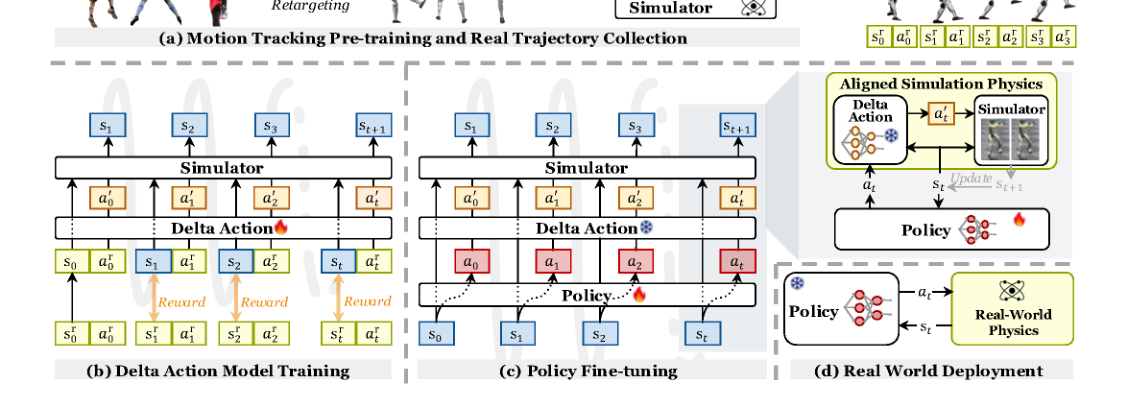
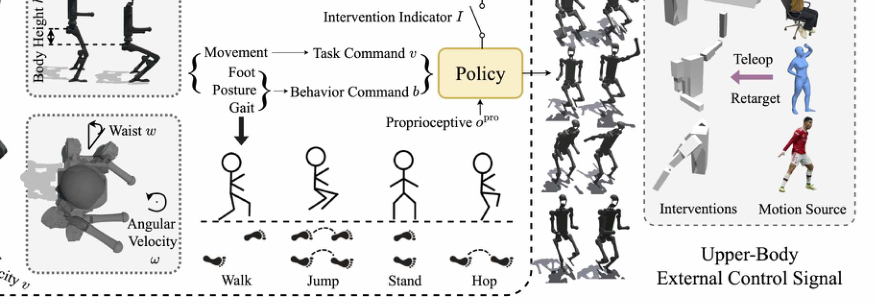
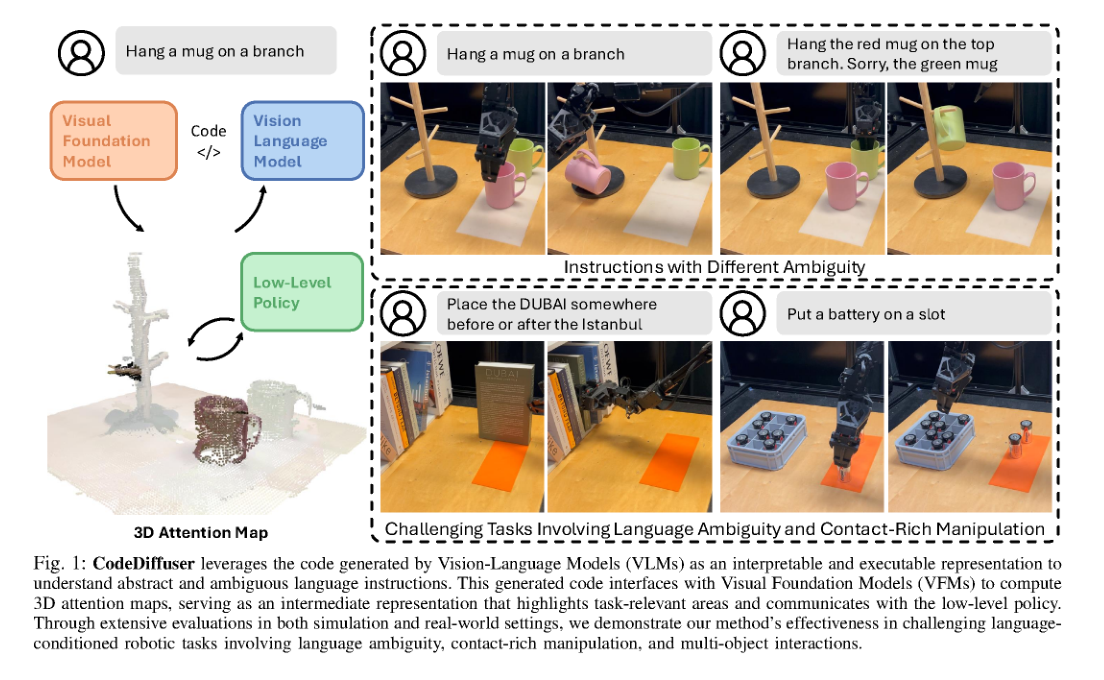
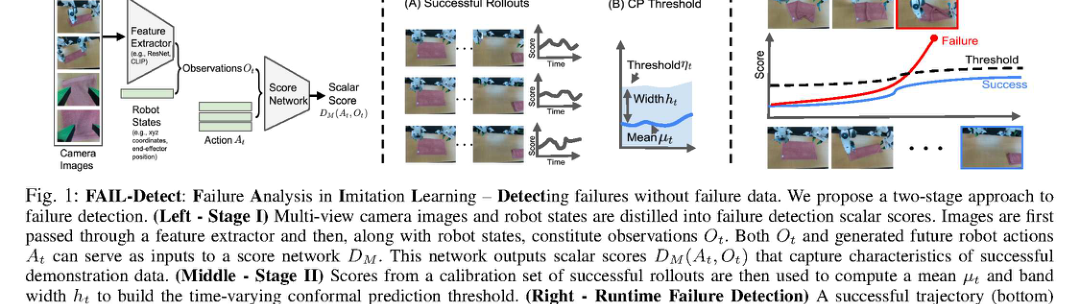
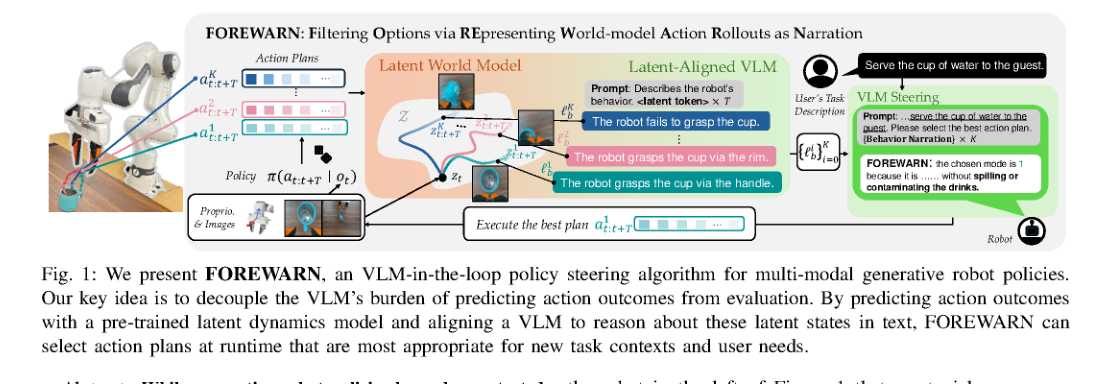
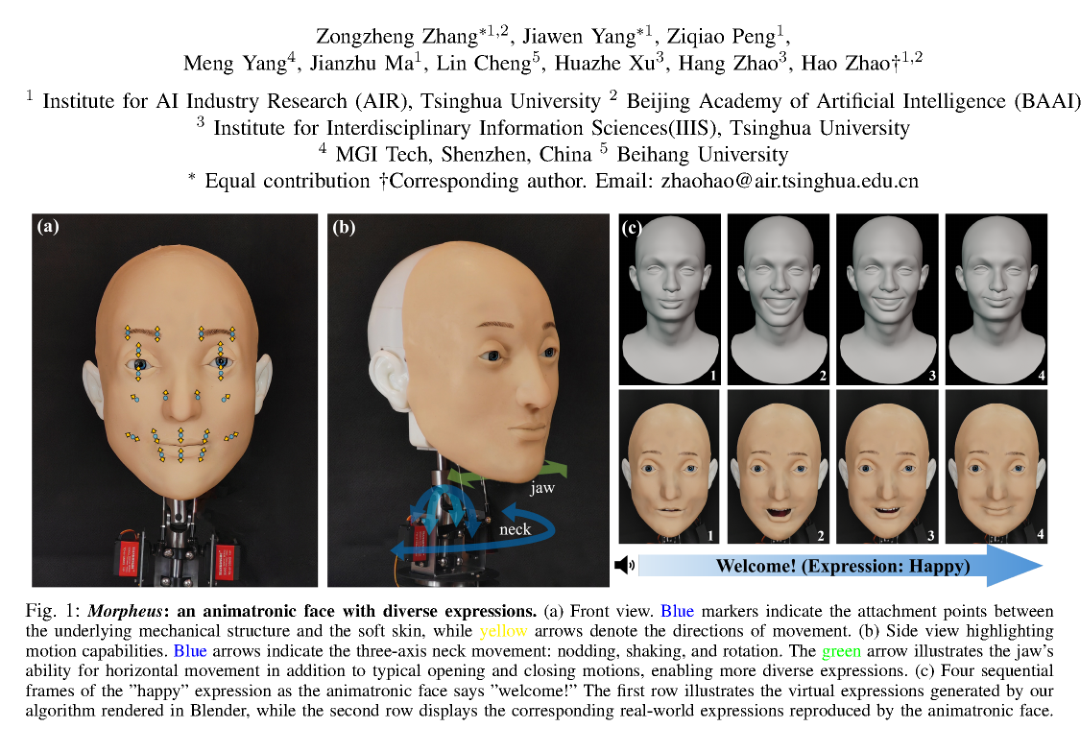
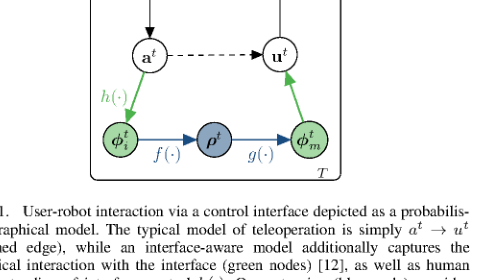
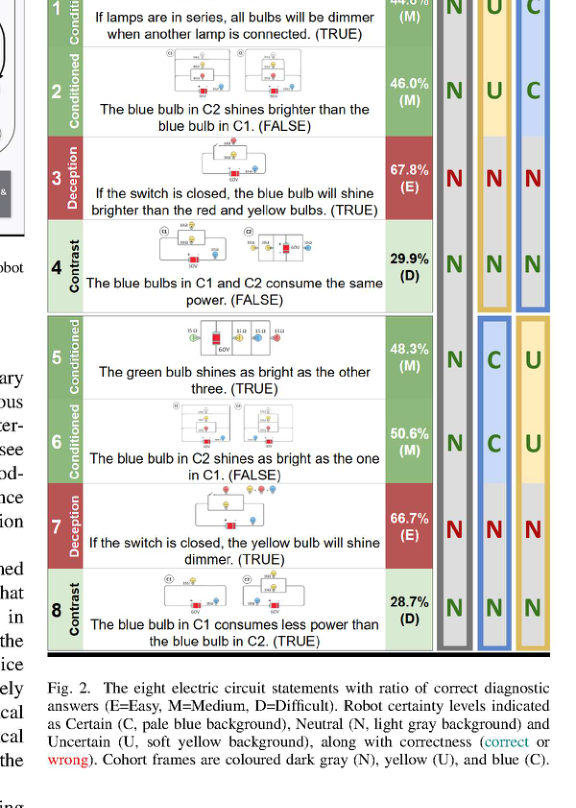
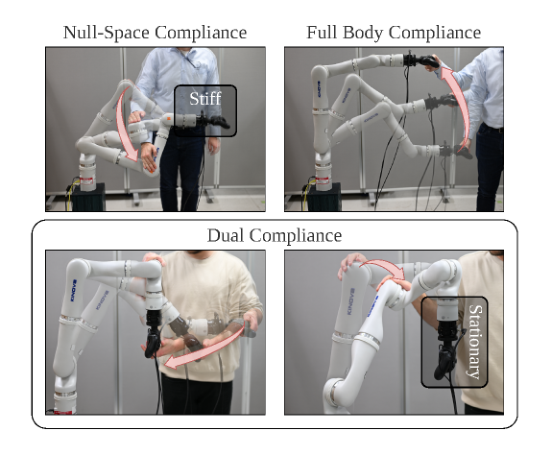
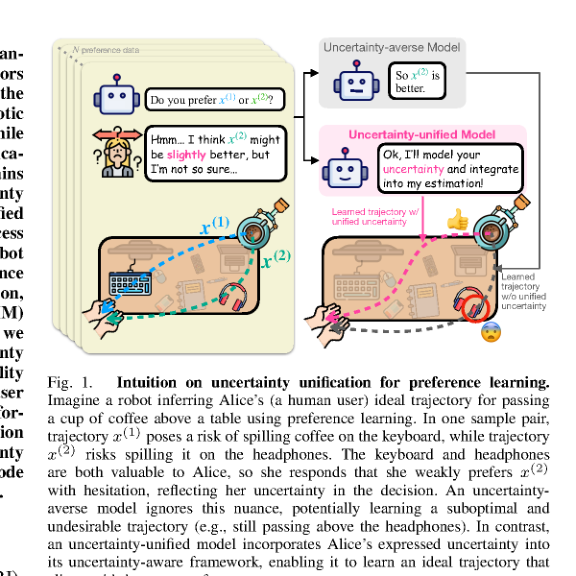
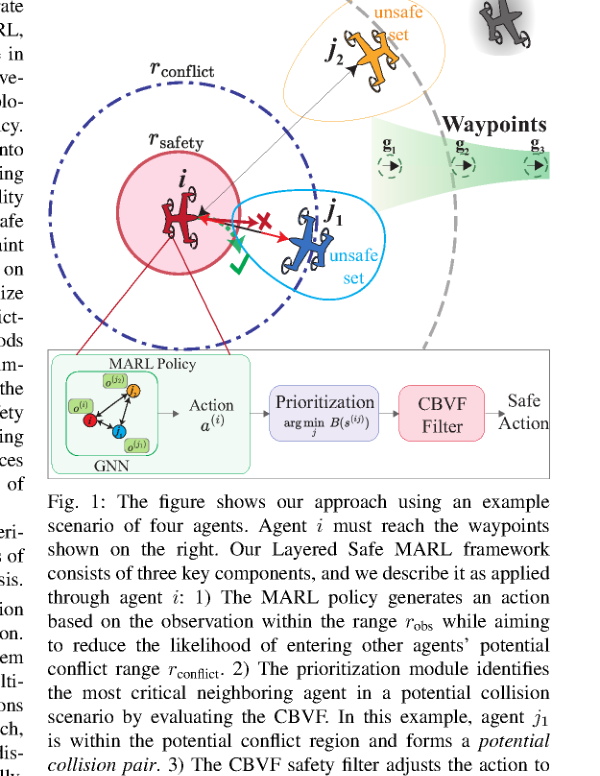
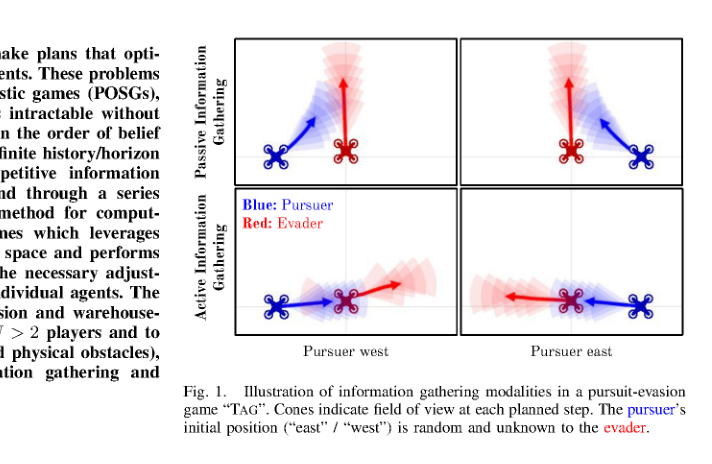
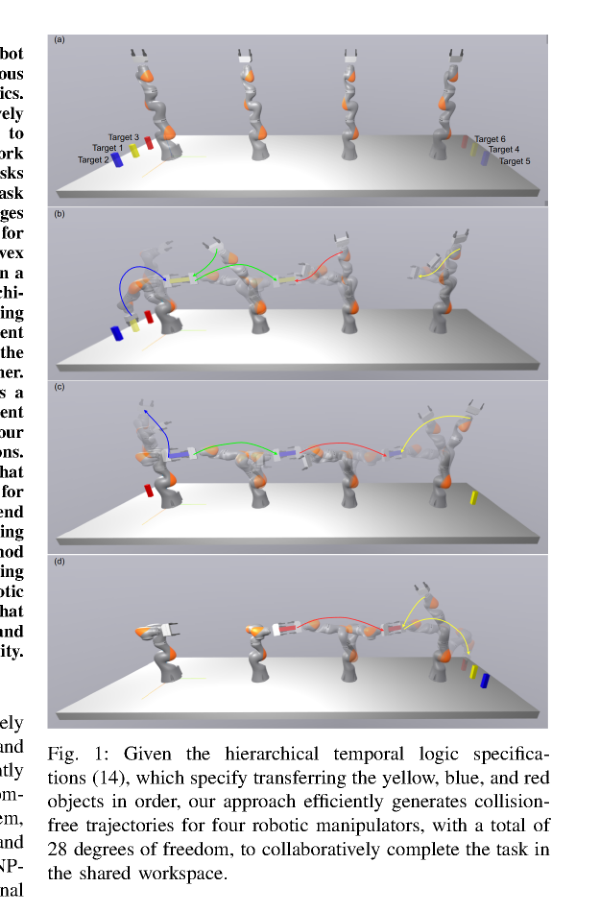
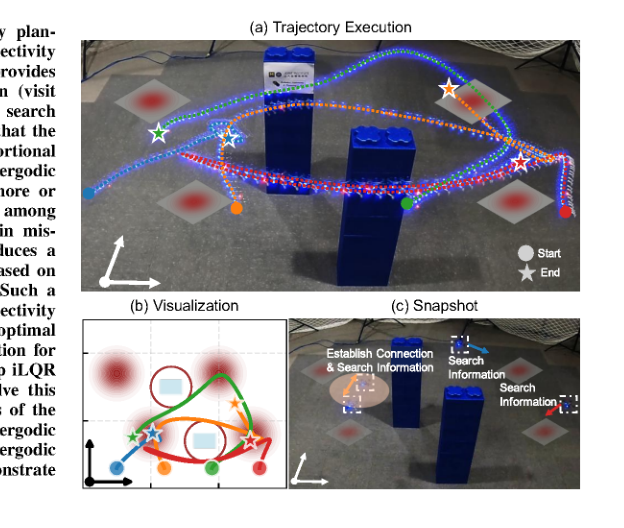
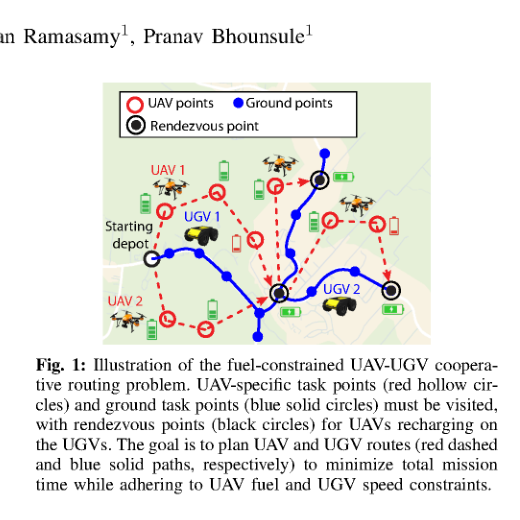
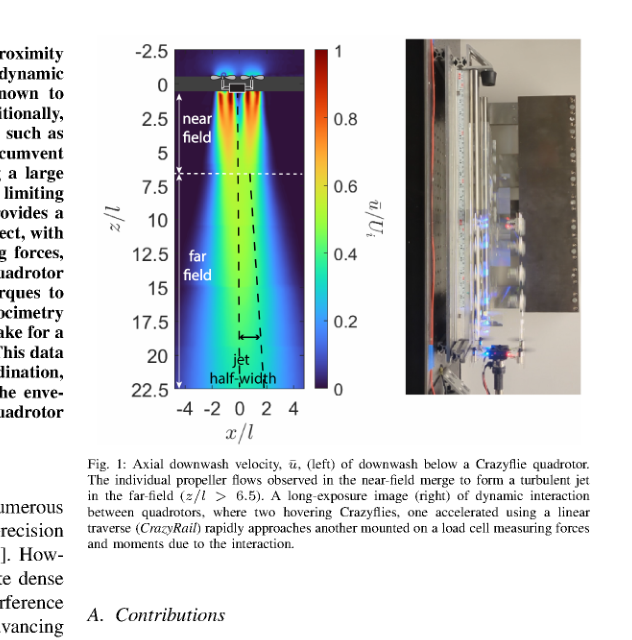
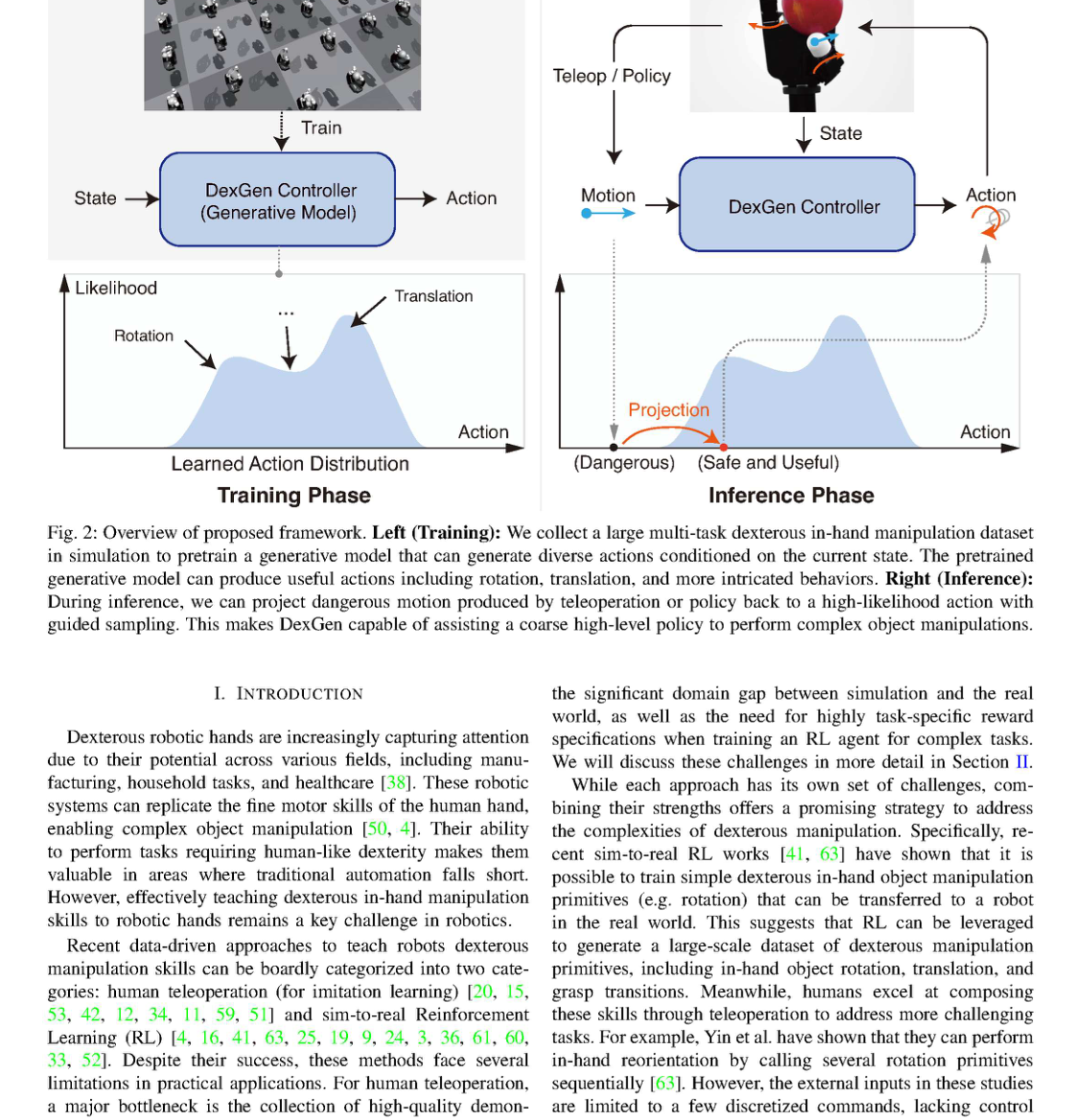
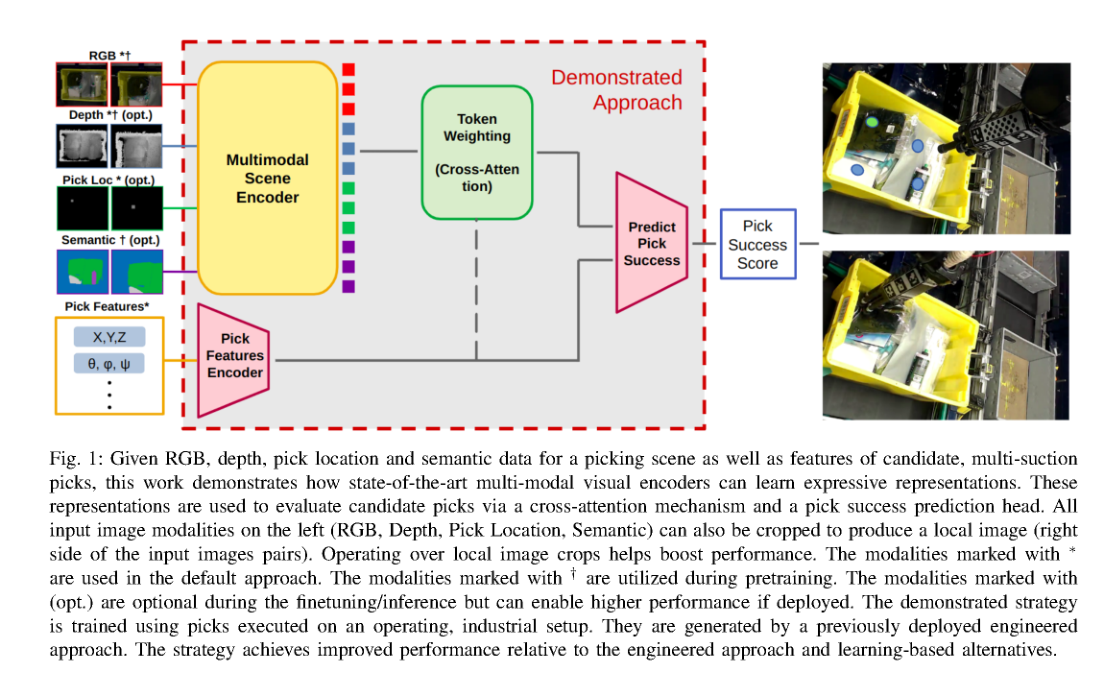
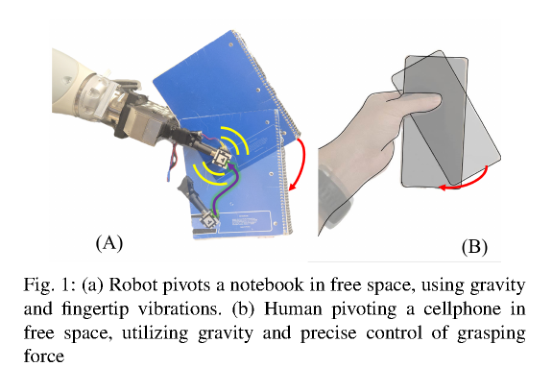
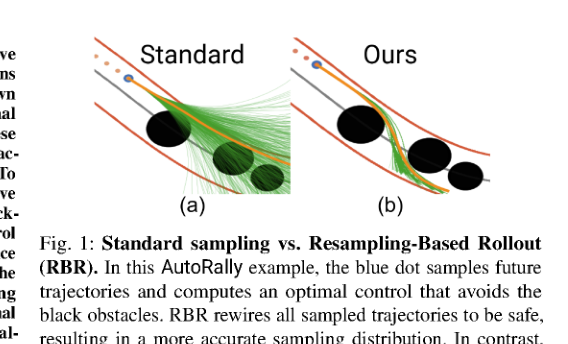
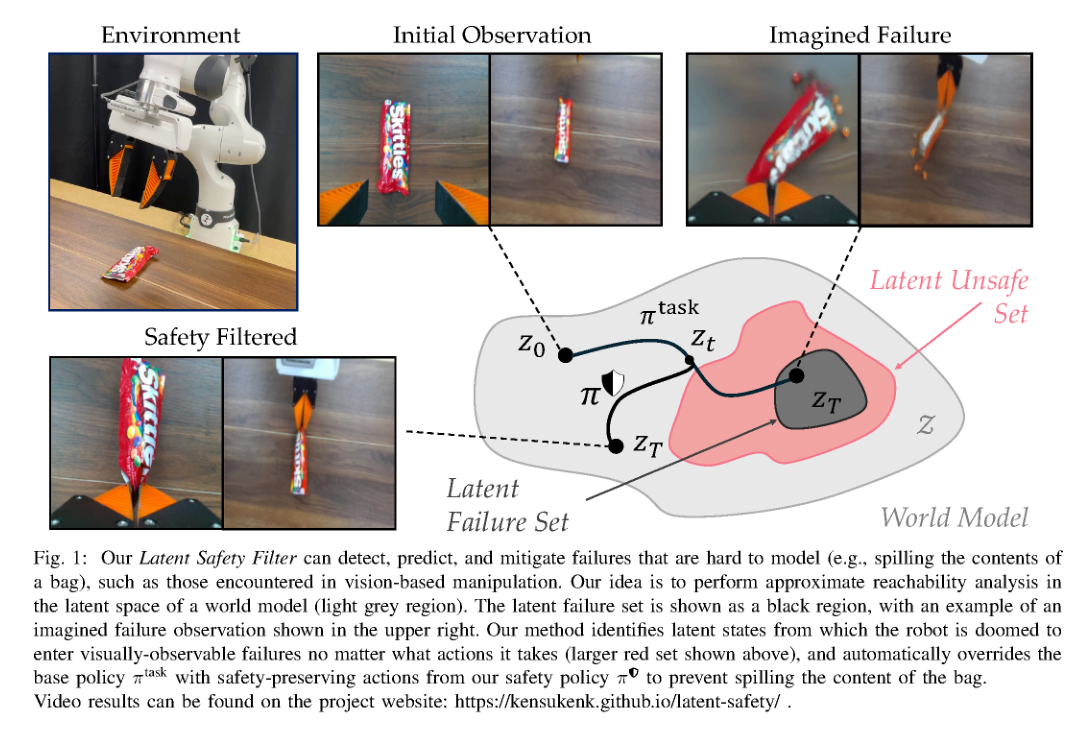
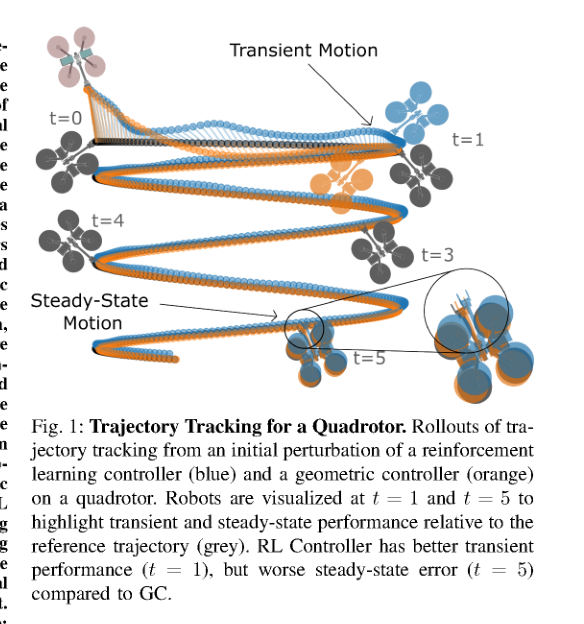
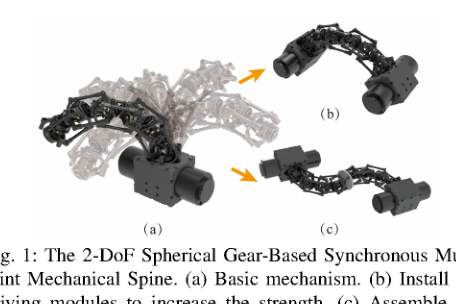
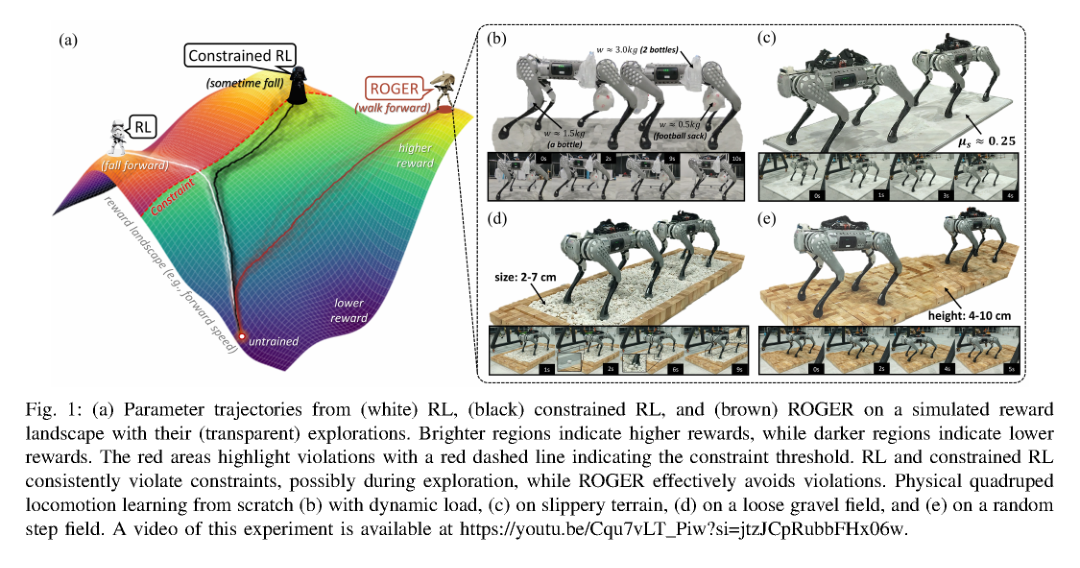
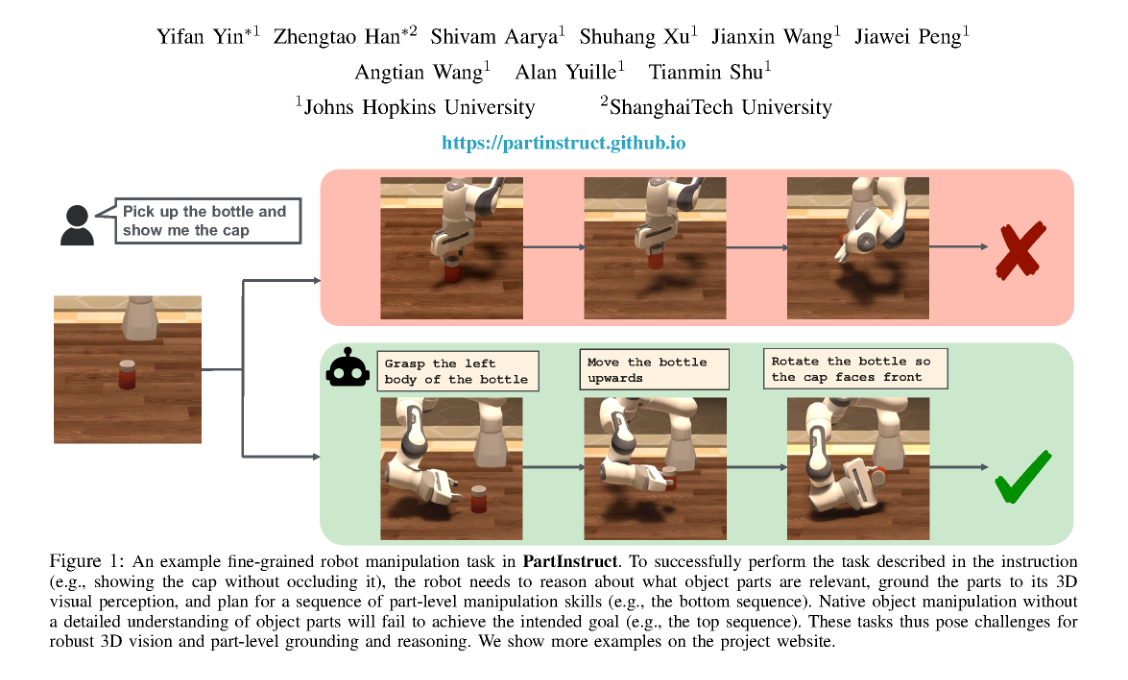
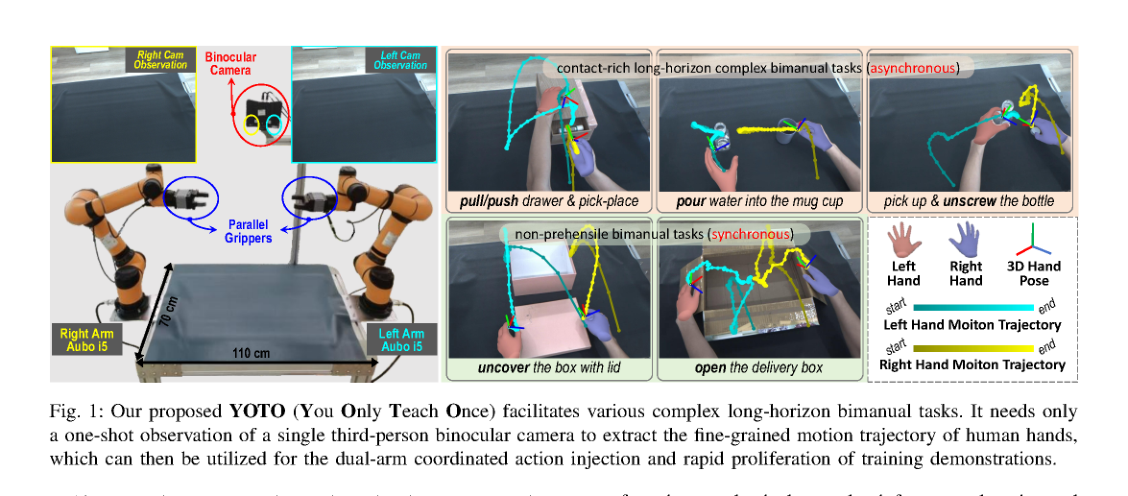
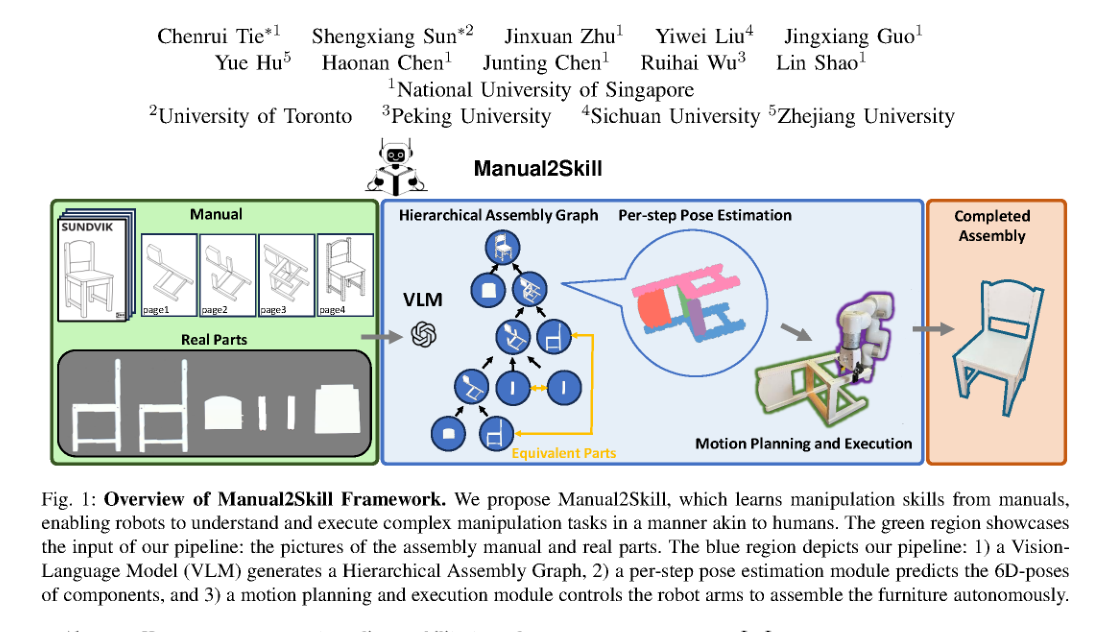
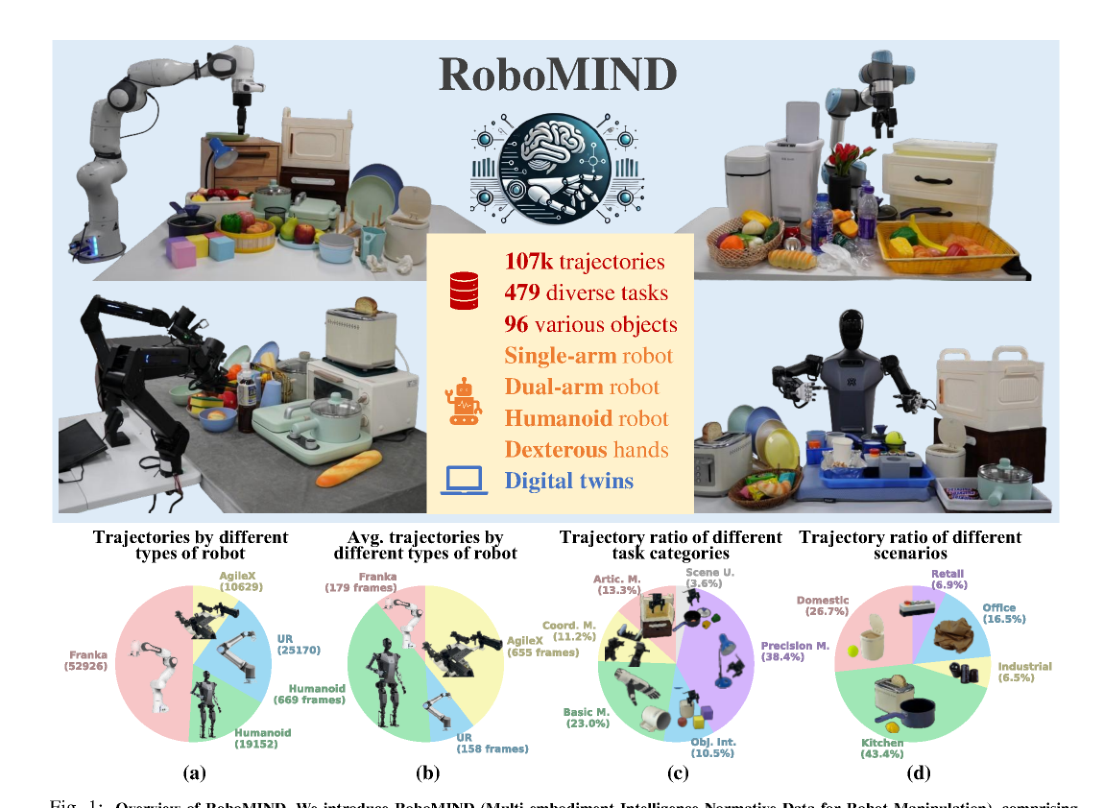
RSS2025Paper 001
Learned Perceptive Forward Dynamics Model for Safe and Platform-aware Robotic Navigation
ETH Zurich † NVIDIA ‡ Max Planck Institute for Intelligent Systems
论文针对腿足机器人在复杂地形中导航时,传统简化动力学与手工代价函数既难调参又难反映平台能力的问题,提出感知式前向动力学模型:结合周围高度几何与本体感觉历史,预测多步未来状态及失败风险,并嵌入零样本 MPPI,以更简单代价实现平台相关的安全规划。ANYmal 上其位姿预测较基线平均提升 41%,粗糙地形仿真导航成功率提升 27%,并展示了仿真到现实迁移;但增益分解文中未充分说明,判断受限于 PDF 文本抽取质量。