精读笔记
Problem Setting
这不是普通的 dynamics learning,而是持续环境变化下的在线对齐问题:模型要一边服务于当前任务,一边跟踪不断变化的动力学,同时还要控制数据效率、安全性和遗忘。真正矛盾在于,探索本身需要依赖模型,但模型又会被不好的探索分布污染;所以越失配越难纠偏。以前方法要么靠 replay 维持历史稳定性,要么接受偏差探索带来的低效率。
Motivation
已有路线的问题是,模型一旦开始失配,后续探索会在错误假设上越滚越偏,replay 只能缓解稳定性,不能改善数据本身的质量。作者的核心观察是:与其让机器人拿着失配模型去试错,不如显式学习‘如果模型对齐,机器人本来会怎么做’,然后把当前动作往那个方向拉。真正缺的是一个在 online 条件下、能把‘动作意图’从‘错误模型下的规划输出’里解耦出来的机制。
Core Idea
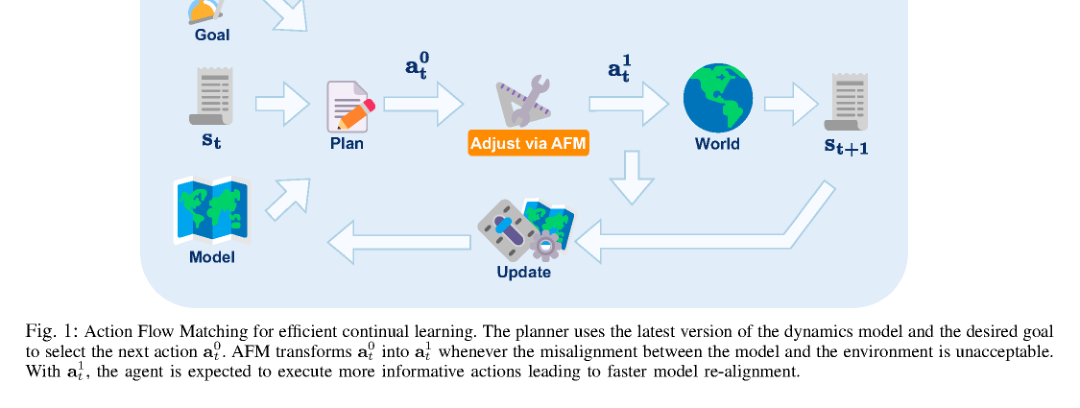
这篇论文把 continual adaptation 的核心目标从“修正 dynamics 参数”改写为“修正 action intent”。它假设:规划器在失配模型下给出的动作并不等于机器人在真实对齐模型下会选的动作,但这两者之间存在可学习的变换。Flow matching 在这里不是为了生成漂亮样本,而是作为一种连续流映射工具,把规划动作拉到更接近真实意图的动作分布上。这个建模方式的变化很关键:它不再要求先把世界建准再行动,而是允许模型在不完美的情况下,通过动作层面的校正维持有效探索。相比传统 continual dynamics learning,它引入的 inductive bias 是“动作可被 regime-conditioned 地重参数化”,而不是“所有误差都必须反映在状态预测器里”。
Method
方法上最关键的不是某个网络结构,而是三件事:一是用已有模型把训练和采样限制在近似可行的动力学区域里,避免无效数据;二是用‘规划动作 vs. intended action’的差异来构造学习信号,让模型学到动作修正而不是仅仅拟合状态转移;三是用当前状态与 transition error 来条件化动态 regime,使动作变换随环境变化而变。这个设计的必要性在于:continual learning 的困难本质上来自分布漂移,而 action correction 直接作用于漂移源头——探索分布本身。它改变的是机器人和环境之间的信息闭环,而不只是模型参数的更新顺序。
Key Insight / Why It Works
最可能的核心贡献不是 flow matching 这个名字本身,而是“把错误模型下的探索变成可学习的动作重定向”。它之所以可能有效,有三个原因:第一,它利用了初始模型提供的近似可行域,避免在无意义空间中学映射,这本质上是 data coverage 的提升;第二,它把 dynamics shift 视为 regime conditioning 问题,等于把误差结构显式化,从而降低单一 policy 在多种环境下的混杂拟合;第三,它让机器人执行的每一步都更接近‘有信息的失败’或‘有信息的偏离’,所以在线学习的信噪比更高。真正的增益很可能主要来自 better inductive bias + better data coverage,而不一定是 flow matching 这个生成范式天然优于别的连续映射器。换句话说,AFM 的价值更像是把 continual learning 的数据采样分布重新组织了,而不只是换了一个更强的回归器。
Relation To Prior Work
它最接近的谱系是 continual model-based RL、online system identification、residual dynamics learning,以及某些用生成模型做动作修正/轨迹修正的工作。真正不同点在于:前者多数把重点放在‘更新模型参数’,后者多数把重点放在‘生成更好轨迹’;AFM 则把二者中间的动作层作为主战场。看起来像是 flow matching + online adaptation 的组合,但本质上是把离线生成模型的连续映射能力,转成了在线机器人控制中的 action realignment 机制。实质创新不在于 flow matching 本身,而在于它被用来重构 continual learning 的信息流。
Dataset / Evaluation
实验覆盖真实机器人平台,而且跨了两类动力学建模范式:UGV 上偏纯数据驱动,quadrotor 上偏物理先验+在线更新。这一点支持了它不是某个单一模型家族的小修小补。评价关注的是在线任务成功率、收敛速度和动态切换后的恢复能力,和它的 claim 基本对齐:即持续适应与更快再对齐。缺点是,评测仍然偏向相对受控的移动平台和地图/场景切换,尚不足以证明它能处理更复杂的长时序 manipulation、接触驱动系统或高度部分可观测环境。
Limitation
它的上限首先受制于初始模型:如果初始模型给出的可行域本身就偏得很厉害,后面的动作校正会在错误的 support 上精修,效果会快速塌缩。其次,它并没有真正解决世界模型遗忘问题,而是借助动作层面的对齐间接缓解;这意味着长期记忆、跨任务迁移和强 OOD 泛化仍然是外部问题。再者,文中的部分收益可能来自更好的数据组织方式、隐式 curriculum 或对动态切换的更快触发,而不是一种新的可证明对齐机制。最后,它的在线部署收益在多大程度上可迁移到需要强规划、强安全约束和高维动作空间的系统,文中未充分说明。
Takeaway
- 这篇论文最值得迁移的 insight 是:在 continual robotics 里,先别急着修世界模型,先修探索分布;很多“模型更新慢”的问题,实际上是因为你采到的数据一开始就不对。
- 另一个可迁移点是 regime-conditioned action correction:当系统存在明显动态切换时,显式建模切换对动作的影响,可能比盲目加大 replay 更有效。
- 最后,它提醒我们,在线学习里最贵的不是参数更新,而是错误数据分布。
一句话总结
AFM 把 continual robot learning 从“在失配动力学上继续探索并修模型”改写成“先用 flow matching 校正动作意图,再用更有信息的数据反向对齐模型”,属于动作层数据重分布而非纯参数更新的一类方法。