精读笔记
Problem Setting
它实际在解决的是‘如何为接触丰富装配/拆卸建立可学习基座’的问题,而不是单个装配任务的控制问题。真正的困难点在于:这类任务既长时序又强接触,错误会在微小对齐、力度和顺序上累积,导致模型很难靠稀疏视觉监督学到稳定策略。以前的方法多半停留在简单抓放或短程技能,遇到接触与失败就退化。这里的关键矛盾是:任务越真实,数据越难采;数据越标准化,场景又越窄。论文选择在这个矛盾里偏向标准化基准。
Motivation
作者的核心观察其实很直接:现有 manipulation 数据集大多太‘轻’,而接触丰富任务真正需要的是能表达物理交互细节的数据。不是再多几个 demo 就够了,而是要有能覆盖接触瞬间、失败边界和子技能结构的数据。于是他们选择从数据层而不是算法层切入,因为在这个方向上,缺口首先是可学习信号,而不是模型容量。
Core Idea
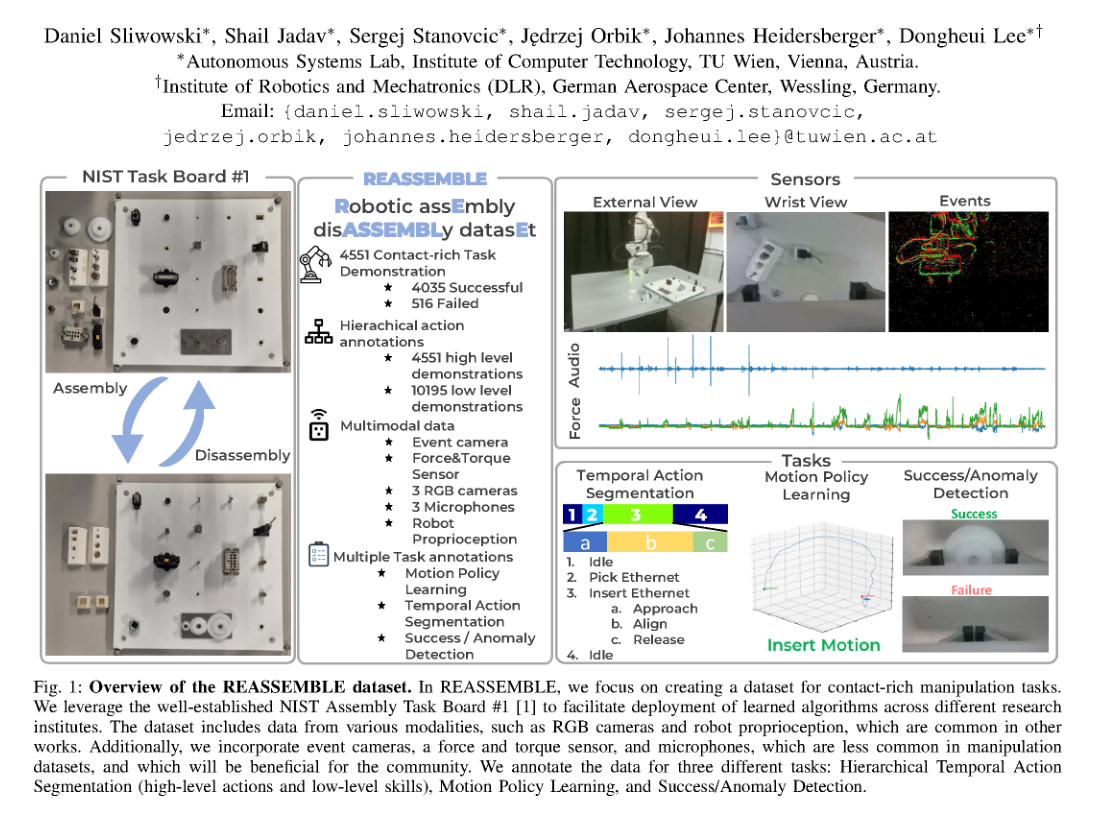
这篇论文的核心思路可以概括为:不要再把接触丰富操作当成纯算法问题,而是先把它变成一个‘有结构的数据问题’。作者选择一个固定、可复现的真实任务板,把装配/拆卸过程拆成统一的动作空间,再用多模态传感把接触信息显式记录下来。这样做的本质,是把原本隐含在机器人-物体交互中的信息外显化,让模型有机会从视觉之外的通道读到接触状态、接触时刻和操作失败。它比传统 manipulation 数据集更像是在为‘接触表征学习’搭一个高约束的数据底座。
Method
方法层面最值得注意的不是某个算法,而是数据建模方式:统一硬件任务板、统一采集协议、统一时序对齐、统一层级动作语义。这样做解决了三件事:一是让接触事件可观测,二是让长时序任务可分段,三是让成功/失败和动作过程一起进入同一个监督体系。它带来的变化是,原本只能做‘看视频学动作’的数据,变成了可以同时服务 policy learning、segmentation 和 anomaly detection 的结构化交互数据。
Key Insight / Why It Works
这篇工作的有效性,核心来自两层东西。第一层是数据覆盖:接触-rich 任务最大的问题本来就是交互变化太多,而它把真实接触过程、失败轨迹和层级动作边界都收进来了,所以对学习系统来说,信号密度比普通 manipulation 数据高很多。第二层是 inductive bias:统一任务板和层级标注会强迫模型在一个稳定物理接口上学习子技能复用,而不是学一堆一次性的轨迹模板。至于事件相机、音频和力矩传感,理论上确实能补足视觉在接触瞬间的盲区,但文中未充分说明它们在最终任务上到底贡献多大;我更倾向于判断,当前最主要的收益还是来自‘真实接触数据 + 标准化组织方式’,而不是某个单独模态的魔法。
Relation To Prior Work
它最接近两条谱系:一条是 robotics dataset / imitation learning 数据集路线,另一条是接触-rich manipulation 与 task segmentation / anomaly detection 的结合路线。真正的不同不在于‘又收集了一个数据集’,而在于它把装配/拆卸作为第一类对象来设计数据,而不是把这类任务塞进通用 manipulation 框架里顺手带过。看起来新的是多模态和多任务,其实这些思想都不新;实质创新是把它们放进一个真正适合接触学习的统一物理任务板里,并且显式加入失败与层级结构。
Dataset / Evaluation
数据集的覆盖面主要体现在多对象、多动作、多模态和成功/失败都包含在内,这一点对接触任务很关键,因为只有失败样本才真的能学到边界和异常。评估上,论文更像是在做‘数据可用性证明’,而不是严格证明某个学习框架 SOTA。它展示了数据可以支持动作分割、运动策略学习和成功/异常检测,也给出真机执行示例来说明数据组织是可落地的。但就 evaluation 而言,它并没有充分回答一个更强的问题:这些模态和标注是不是确实带来了显著的泛化提升,还是只是把已有任务换了一个更难的场景。
Limitation
这篇论文的上限由数据定义:它把复杂操作压缩到一个标准任务板上,因此很适合做基准,不一定适合代表真实世界装配/拆卸的全分布。方法依赖的前提是接触结构可以被标准化、示教可以稳定采集、并且任务边界可以人工标注;一旦转向更开放的工件、非固定装配条件或长程任务链,这套组织方式的可扩展性就会下降。另一个关键问题是,作者强调多模态和多任务,但没有严格拆解每个部分的边际贡献,所以当前很难判断到底是‘更好的表示’还是单纯的数据规模/覆盖度在起作用。换句话说,核心能力很可能主要来自 data coverage,而不是某种新的学习范式。
Takeaway
- 这篇工作最值得记住的不是某个模型,而是一个判断:接触丰富操作要想真正进入学习范式,关键不是再抽象一点,而是把物理交互本身记录得更完整、更结构化。
- 它推动的方向更像是‘标准化真实接触数据基础设施’而不是‘新控制范式’。
- 后续真正值得做的,是证明这些模态和层级标签能否在更开放的任务链上带来稳定泛化,而不是只在固定 board 上做漂亮演示。
一句话总结
REASSEMBLE 的位置不是提出新算法,而是用标准化真机多模态接触数据把装配/拆卸从“难以学习的长时序控制问题”推进成“可被统一建模的学习问题”。