精读笔记
Problem Setting
这篇论文实际在解决的是静态 visuomotor policy 到动态移动操作平台的部署鸿沟。真正难点不是单次抓取,而是“策略输出如何在运动底座上仍然对准世界”:低算力导致推理延迟,动作 chunking 导致反应慢,平台自身抖动和移动导致末端目标系改变。以前方法要么依赖动态平台上的专家示教,要么依赖更重的闭环规划/控制栈,但都把成本和复杂度推高了。这里的关键矛盾是:训练希望静态、简单、可规模化;执行却要求动态、实时、强对齐。
Motivation
作者的核心观察不是“动态平台很难”,这个太泛;而是静态训练策略在动态平台上失效的根因是执行期时空错位,而不是数据集本身缺少某种抽象知识。既然示教数据主要在静态平台上采集,那就没必要把困难前移到训练阶段去硬吃;更合理的做法是保持静态训练的效率,把难点放到执行时用系统层补偿掉。这个动机非常务实:在机器人上,训练数据贵、算力紧、平台运动又不可控,执行期修正比重新采集动态数据更可扩展。
Core Idea
STDArm 的核心想法是把“动态性”从 policy learning 问题,转成 execution-time alignment 问题。也就是说,不要求策略在训练时就见过动态平台,而是在执行时通过高频控制、短期运动预测和时延校准,把静态策略的动作重新映射到当前真实状态上。这个思路的价值在于:它默认策略本身已经学到了任务意图,真正失效的是动作被执行到错误的时空坐标里。于是系统只需要补齐这个坐标错位,而不是重做整个策略学习过程。和很多动态操作方法相比,它不是“让模型学会所有动态”,而是把动态补偿外包给一个轻量、可插拔的执行层。
Method
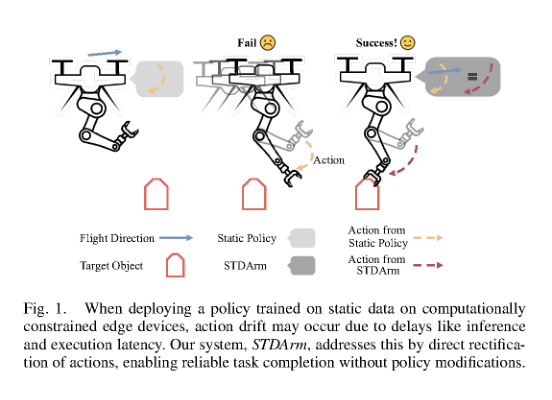
方法上真正必要的是三件事,而不是一堆模块。第一,action manager:它解决策略推理低频、输出与控制回路不同步的问题,把异步 policy 变成可持续执行的高频控制流;没有这层,后面的补偿没有落点。第二,prediction-based stabilizer:它解决平台底座在动导致末端动作漂移的问题,通过短时未来位姿预测把动作预先校正;这一步的意义是把 base motion 从误差源变成可显式建模的外生变量。第三,online latency estimation:它解决执行链条中最隐蔽但最致命的错位——动作不是对当前状态,而是对过去状态做出的,必须在线估计并校准。整体上,这不是重新训练一个统一 policy,而是在控制闭环里插入一个执行期的对齐层。
Key Insight / Why It Works
最关键的 insight 是:动态平台上的失败,往往不是因为 policy 不够强,而是因为 policy 的动作是在错误时间、错误位姿、错误延迟下执行的。STDArm 直接针对这三个错位源头做修正,所以它的收益主要来自 better inductive bias + test-time compute,而不是新表示学习。这里最可能是核心贡献的是“高频控制 + 运动补偿 + 时延估计”的组合拳;单独看每个模块都不新,但组合后把任务定义从“学动态操作”改成“修正静态策略的执行坐标系”,这才是方法成立的根本。相对而言,action interpolation 和 temporal ensemble 更像把高频控制做平滑、做稳定的工程增强;真正决定能否落地的是动作管理和时延补偿。换句话说,主要增益很可能来自系统级对齐,而不是一个更聪明的 policy。
Relation To Prior Work
它最接近的谱系不是传统的 manipulation policy,而是‘执行期修正’和‘视觉伺服/残差控制’那一支。和 ACT、Diffusion Policy 这类方法相比,它没有在策略本体上追求更强的时序建模,而是承认策略输出本身可以保持不变,只在执行层做对齐。和那些试图减少 diffusion 步数、提高推理频率的方法相比,STDArm 的重点不是让 policy 更快生成,而是让生成出来的动作更不容易过期。看起来新的是系统名字和组合,实质上是把 temporal ensemble、插值、视觉 SLAM、短期预测和时延估计重组为一个移动操作 wrapper。真正创新点在于这套重组对应了动态平台的实际误差结构,而不是一个单纯的算法点子。
Dataset / Evaluation
评估覆盖了两类机械臂、四类移动平台和三项需要较高精度的操作任务,并且包含真机无人机场景,这一点比单一地面移动平台更有说服力。它至少验证了两件事:一是静态策略在动态平台上的确会明显退化;二是执行期补偿可以把退化拉回来。这个评价对“系统能否迁移到不同平台”有一定支撑,但对“方法是否学到了更强的动态表征”支撑并不强,因为 benchmark 主要测的是执行稳定性,而不是新任务泛化或长时规划能力。
Limitation
最大限制是它依赖很强的前提:短时运动可预测、位姿可稳定估计、外参可准确标定、任务时间尺度不长。只要平台运动模式变得更剧烈,或者感知出现遮挡/漂移,补偿链条就会失效。其次,论文把“迁移静态策略到动态平台”讲得很强,但实际上它更像是在动态平台上加了一个控制壳;策略本身并没有变得更会处理动态世界,所以泛化上限取决于补偿层,而不是 policy。最后,增益归因仍不完全清晰:从已有描述看,时延校准和更高控制频率可能贡献很大,真正的“预测补偿”未必是主要增益来源。
Takeaway
- 这篇工作最值得迁移的不是某个网络,而是一个判断:在很多移动操作场景里,问题的主战场不在 policy learning,而在 execution alignment。
- 未来如果要做更复杂的动态操作,优先考虑先把时空对齐、延迟补偿、底座运动建模做扎实,再谈更大的 policy。
- 第二个可迁移 insight 是:对低算力平台,test-time correction 往往比端到端重训更划算。
- 第三,真正能规模化的动态操作系统,可能不是“训练一个能处理一切的动态策略”,而是“让静态策略在执行层变得动态可用”。
一句话总结
STDArm 代表的是一种执行层迁移路线:不重做动态策略学习,而是用高频控制、运动预测和时延校准,把静态训练的 visuomotor policy 变成能在移动平台上实时工作的系统。