精读笔记
Problem Setting
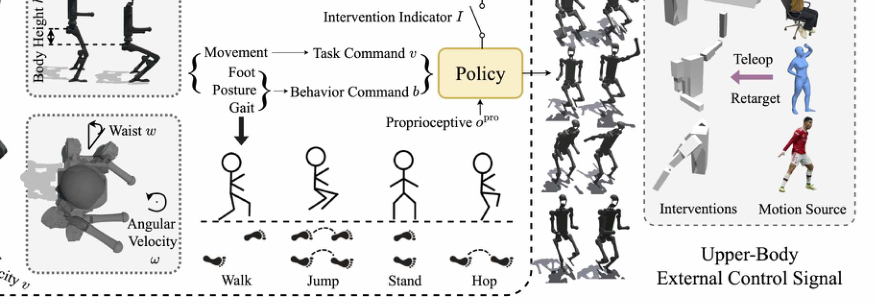
它真正面对的是 humanoid 的“多样步态与可控性”之间的矛盾:一方面我们想要 walking/jumping/hopping/standing 这些行为都能稳定出现;另一方面又希望这些行为不是固定模板,而是能在频率、足部高度、身体姿态等维度上连续调节。再往前一步,还希望外部上半身控制能实时插入而不把下肢节律打乱。以前方法卡住的地方就在于它们要么只学单一 gait,要么虽然有多个技能,但技能切换和外部接管都不稳,导致控制器无法作为统一底座。
Motivation
作者的动机非常明确:现有 humanoid locomotion 太像“能走就行”的 demo,而不是一个可扩展的平台。缺的不是再多一点速度控制,而是像人类那样可以细粒度调 gait 风格、改变姿态,并且在走路的同时让上半身做别的事。换句话说,作者看到的缺口是“控制维度太少 + 控制边界太死”。
所以他们不是在已有控制器上做微调,而是试图定义一个更像“基础运动内核”的 controller:既能统一多 gait,又能对上半身开放接口。这种思路的出发点不是追求某个 benchmark 最优,而是补齐 humanoid 作为通用平台所缺的控制抽象层。
Core Idea
这篇论文的核心思想是:不要把 humanoid locomotion 当作“单一轨迹生成”,而要当作“在一个手工组织好的行为坐标系中做条件控制”。它的统一性来自命令空间,而不是来自更复杂的物理推理。换句话说,作者不是去让策略自己发现 walk/jump/hop 的边界,而是先把这些边界和可调参数显式编码进去,再用 RL 把这个命令空间和真实的 whole-body 动作对齐。
这和很多 prior 的本质差别在于:prior 往往只把速度作为主命令,风格变化是副产物;这里则是把风格参数本身变成一等公民。再加上 intervention training,策略学到的不是“上半身永远由我控制”的脆弱闭环,而是“上半身可能随时被外部接管,但下肢节律必须保持”的分工式闭环。这个 inductive bias 很关键,因为它直接提高了可组合性和实机可用性。
Method
关键机制只有三件事,且都服务于同一个目标:让 humanoid 的动作空间变得可控、可插拔、可组合。第一,命令空间把 locomotion 的风格与姿态参数显式化,解决的是“策略不知道该跟踪什么”的问题;它让不同 gait 之间共享表示,但保留可调维度。第二,对称性约束把左右腿的结构先验注入策略,解决的是“学出来的 gait 太自由导致不稳”的问题;它不是创新点核心,但对 humanoid 这类强对称系统有实用价值。第三,intervention training 则把外部控制视作训练扰动,解决的是“上半身被接管时策略会崩”的问题;它的核心变化是把 whole-body controller 从单一闭环改造成可被外部信号打断的鲁棒闭环。
需要强调的是,这里真正有价值的不是这些模块本身,而是它们共同构成了一个新的控制接口:下肢负责稳定 locomotion,上半身允许外部控制穿透,策略只需保证两者不互相破坏。
Key Insight / Why It Works
我认为真正起作用的核心不是对称性损失本身,也不是某个单独 reward trick,而是“命令空间重构 + 干预分布训练”这两个机制叠加后的归纳偏置。命令空间重构把连续控制问题从高维动作生成降成了少量可解释的行为轴,减少了策略需要自己隐式解耦的负担;干预分布训练则把上半身的外部接管变成训练时就见过的分布扰动,因此 policy 不会把上半身锁死成自己的内部控制变量。
从归因上看,最可能是核心贡献的是这两个机制:一个负责可控性和可组合性,一个负责鲁棒性和接口化。对称性 loss 更像稳定器,帮助 gait 结构更规整,但单独它很难解释“多 gait + 外部干预”都能成立;curriculum 也更像训练效率增强,属于辅助项。换句话说,这篇工作更像是把 humanoid control 从“单策略拟合运动”提升为“结构化条件控制”,增益主要来自 inductive bias 和训练分布设计,而不太像纯粹靠更大模型或更多数据硬堆出来的 scaling。
Relation To Prior Work
它最接近的路线其实有两类:一类是 model-based humanoid control,擅长显式动力学和接触规划,但通常依赖固定接触序列、在线优化开销大,且不擅长丰富风格控制;另一类是 RL-based locomotion,能学到很强的速度跟踪和一定的鲁棒性,但命令空间通常很窄,更多是在“会走”的层面上做优化。
这篇论文的真正不同点不是又加了一个新的 gait,而是把“多 gait + 风格参数 + 上半身外部接管”放进同一个 policy 框架里,并通过训练分布设计让它真的能转移到真机。它有明显的谱系继承:命令条件策略、对称先验、干预鲁棒训练,这些思想都不新;新的是把它们重组到 humanoid whole-body control 这个更难的设定里,并且把“接口化”作为核心目标,而不是副目标。
Dataset / Evaluation
评价重点不在单一仿真分数,而在覆盖范围:四类 gait、多个姿态/节律参数、以及有无上半身干预的组合都在真机上验证。这个设计比普通 locomotion benchmark 更接近作者 claim,因为它测试的不是“会不会走”,而是“能不能在多命令、多 gait、外部插入的情况下仍然稳”。
但也要注意,评价主要支持的是“受控命令跟踪”和“干预鲁棒性”,并不能完全证明它已经具备更一般的长期任务能力。尤其是 loco-manipulation 的部分,更像接口可用性验证,而不是复杂任务闭环能力验证。
Limitation
这个方法的隐含前提很强:第一,行为空间必须能被手工拆成少数稳定、可解释的控制轴;如果任务需要更开放式的动作语义,这种命令空间可能会立刻不够用。第二,它默认上半身干预可以被建模成随机插入/噪声式替换,但真实的 loco-manipulation 往往是有明确任务语义的,二者分布差异很大。第三,统一策略的边界并不完全统一——hopping 还要单独处理,说明多模态接触动力学的统一建模能力有限。第四,文中未充分说明组合泛化到底是结构化泛化还是组合覆盖足够多后的插值效果,因此其“general”有一定工程成分,增益来源不清的部分主要在于数据覆盖与训练课程,而非一个真正新的控制理论。
Takeaway
- 1) 这篇论文最值得记住的不是某个单点技巧,而是它把 humanoid locomotion 变成了结构化条件控制问题。
- 2) 真正的贡献是控制抽象层:把 gait 风格、姿态参数和上半身接管组织进统一接口。
- 3) 增益更像来自 inductive bias 和训练分布设计,而不是纯 scaling。
- 4) 未来值得迁移的 insight 是:如果想让机器人从“会动”走向“可用”,重点不是多学几个动作,而是先设计好可组合、可插拔、可解释的控制坐标系。
一句话总结
HuGWBC 的位置是:把 humanoid whole-body locomotion 从“单一跟踪型控制”推进到“命令空间驱动的可组合控制”,其真正贡献在于用统一命令空间和干预鲁棒训练把多步态、细粒度姿态调节与上半身外部接管整合到同一个可部署策略里。